Go 堆内存管理浅析
The Go Memory Model Advice Programs that modify data being simultaneously accessed by multiple goroutines must serialize such access. To serialize access, protect the data with channel operations or other synchronization primitives such as those in the
syncandsync/atomicpackages. If you must read the rest of this document to understand the behavior of your program, you are being too clever. Don't be clever.劝告程序员不要“聪明反被聪明误”,也就是说:
- 不要过度依赖复杂的内存模型细节 如果你发现必须钻研文档的剩余部分才能理解程序的行为,那说明你的设计过于“巧妙”——代码依赖了那些隐晦的、容易出错的机制。这提醒我们,如果为了解决并发问题你需要理解复杂的内存模型,那么可能你的方案不够直白、稳健。
- 保持简单明了的设计 直接使用通道、锁、或者 sync/atomic 等简单的同步原语来序列化数据访问,可以使程序更易于理解、调试和维护。简单直观的代码有助于避免由数据竞争引起的问题,而不是依赖于编译器或运行时对竞态行为的具体处理方式。 总结来说,最后两句的意思是:“不要过于花哨或依赖微妙的内存模型行为;如果为了让程序的行为显得合理,你不得不深入研究文档,那你就是太“聪明”了。保持简单,使用标准的同步机制,才是解决并发问题的稳健之道。”
设计理念
Go 的内存分配器的设计理念起源于 Google 主导设计的基于线程缓存的内存分配机制 TCMalloc,但在部分实现细节上存在一定的差异。这个差异主要是由于 Go 语言的内存分配和释放不是由开发人员通过代码显式执行的, 完全依靠编译器与运行时的配合来自动处理。即依靠内存分类器和 垃圾收集器(GC/Garbage Collector)两大组件完成内存的分配和回收。
// src/runtime/malloc.go
// Memory allocator.
//
// This was originally based on tcmalloc, but has diverged quite a bit.
// http://goog-perftools.sourceforge.net/doc/tcmalloc.html
分配方法
编程语言的内存分配器一般包含两种内存分配方式,一种是线性分配(Linear Allocation),另一种是空闲链表分配(Free-List Allocation),这两种分配方法有着不同的实现机制和特性。
线性分配
线性分配是一种高效且实现简单的内存分配方式,但有较大的局限性。当使用线性分配器时,只需要在内存中维护一个指向内存特定位置的指针,如果用户程序申请内存,内存分配器只需要检查剩余的空闲内存、返回分配的内存区域并修改指针在内存中的位置。
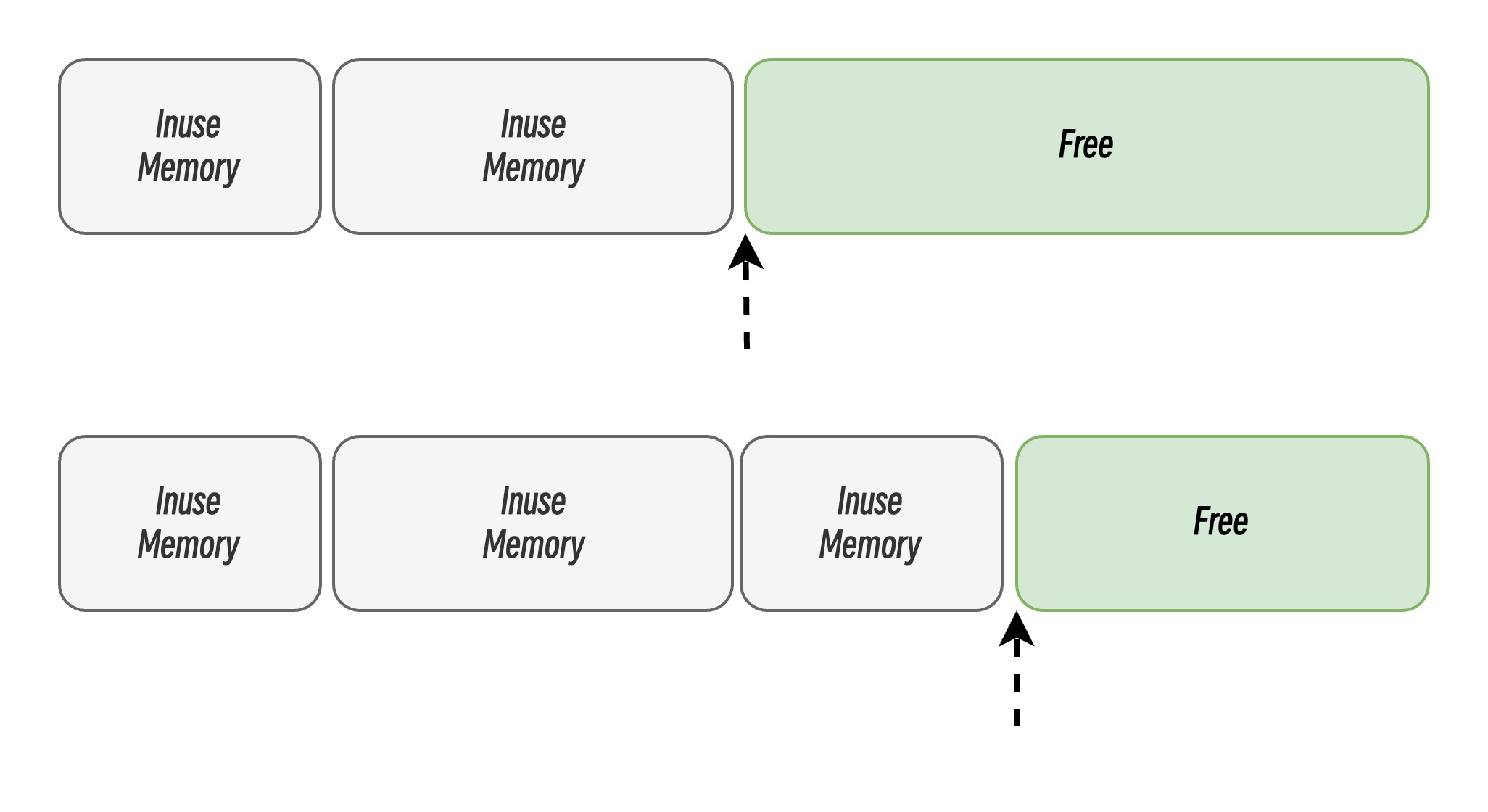
这种简单的分配方式使得内存能被高效地分配,但是线性分配也存在一定的缺点,即无法在内存被释放后被重用。因此部分语言会通过引入 GC,选择合适的垃圾回收算法,通过定期合并空闲的内存碎片,以实现重用的目的,有效地解决了无法重用的问题,提高了内存利用率。
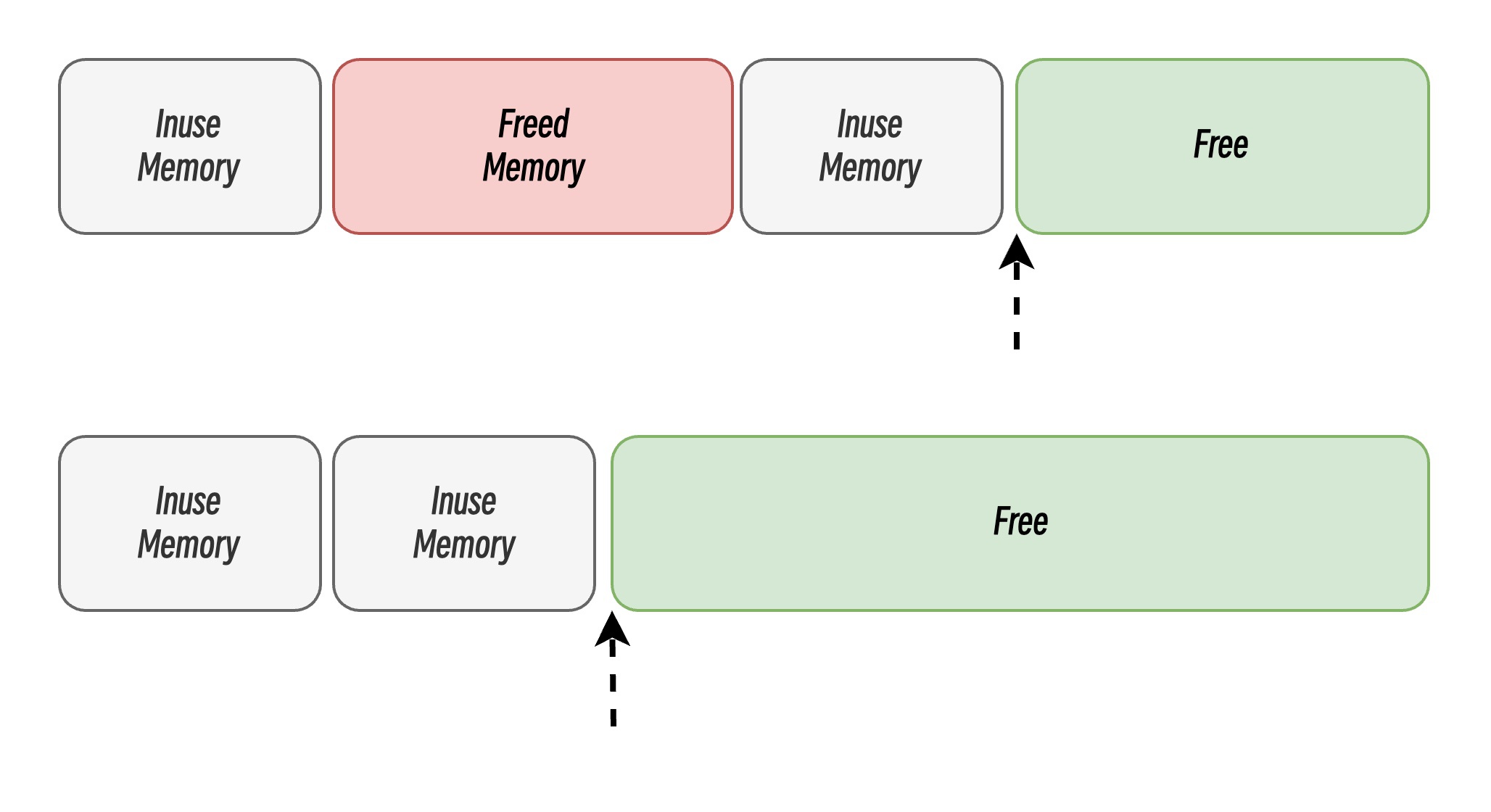
空闲链表分配
空闲链表分配(Free List Allocation)是一种动态内存管理方法,用于在程序运行时分配和释放内存块。其核心思想是通过维护一个链表来记录当前可用的空闲内存区域,并根据需要从链表中分配或回收内存。系统维护一个空闲链表(Free List),链表的每个节点代表一个空闲的内存块。当程序申请内存时,系统遍历空闲链表,找到足够大的空闲块。当内存被释放时,系统将其重新加入空闲链表,并尝试与相邻的空闲块合并。空闲链表分配通过合并相邻的空闲内存防止内存碎片化,通过遍历寻找可用空闲内存块有效地解决了线性分配中已释放内存块无法重用的问题。
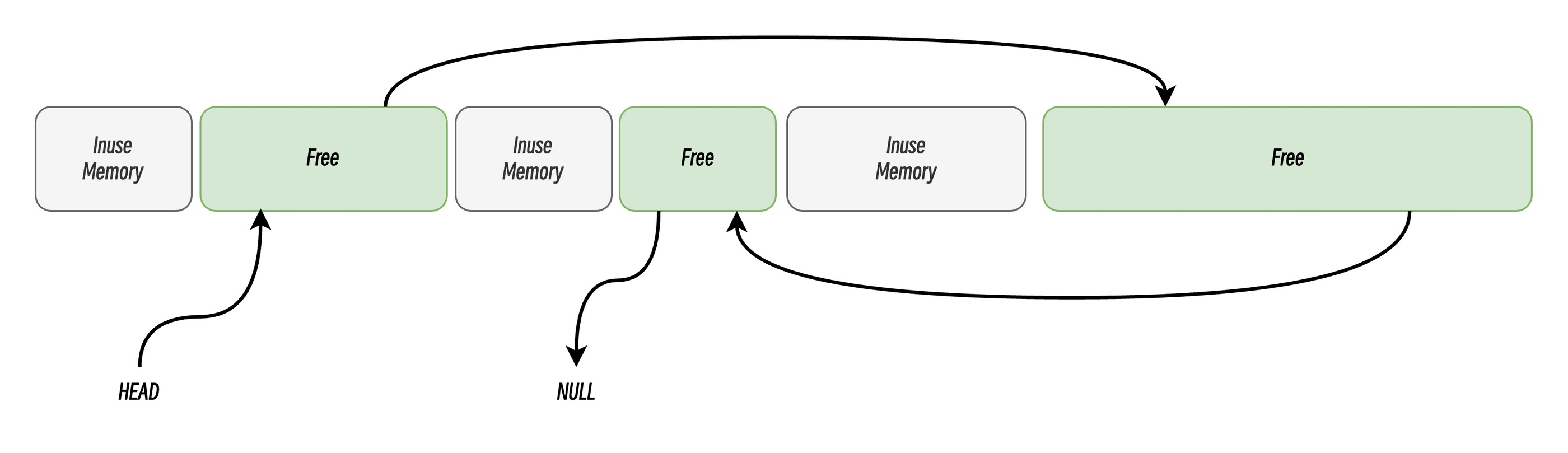
当程序申请内存时,系统遍历空闲链表,找到足够大的空闲块。常用的搜索策略包括:
- 首次适应(First-Fit): 从链表头开始遍历,选择第一个大小大于申请内存的内存块;
- 循环首次适应(Next-Fit):从上次遍历的结束位置开始遍历,选择第一个大小大于所申请内存的内存块;
- 最优适应(Best-Fit): 从链表头遍历整个链表,选择最合适的内存块;
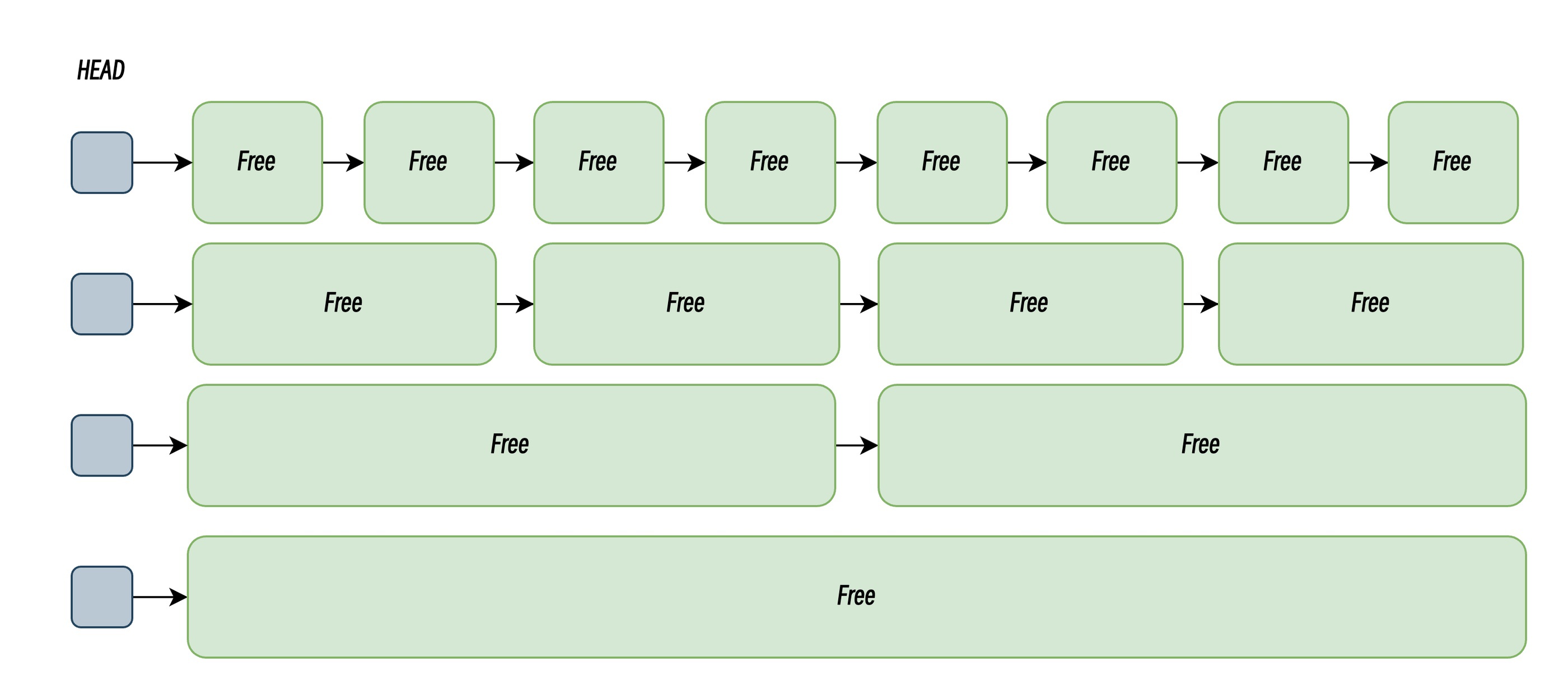
此外,部分分配器为了高效地管理内存,衍生出将内存块按大小分割成多个链表的管理方式,每个链表中的内存块大小相同,申请内存时先找到满足条件的链表,再从链表中选择合适的内存块,被称为隔离适应(Segregated-Fit)。隔离适应策略通过分类管理内存块,在高频小内存分配场景中显著提升性能。
分层内存管理
对象大小分级
Go 语言的内存分配器会根据申请分配的内存大小采用不同的分配路径,运行时根据对象的大小将对象分成微对象、小对象和大对象三种:
| 类别 | 大小范围 | 分配方式 | 管理组件 |
|---|---|---|---|
| 微小对象 | (0, 16B) | 批量线性分配(Tiny Allocator) | mcache(本地缓存) |
| 小对象 | 16B, 32KB | 隔离适应,按尺寸类别(Size Class)分配 | mcache → mcentral |
| 大对象 | (32KB, +inf) | 直接分配连续内存块 | mheap(全局堆) |
因为程序中的绝大多数对象的大小都在 32KB 以下,分配不同大小的内存块的开销不同,因此区分大对象和小对象可以针对性优化内存分配的策略,提高内存分配器的性能。
多级缓存
前面说到 Go 的内存分配器的设计理念参考了 TCMalloc,采用了多级缓存的设计,旨在平衡内存分配的速度、效率和并发安全性。Go 的内存分配器分别引入了线程缓存(Per-P Cache)、中心缓存(Central Cache)和页堆(Page Heap)三个组件分级管理内存:
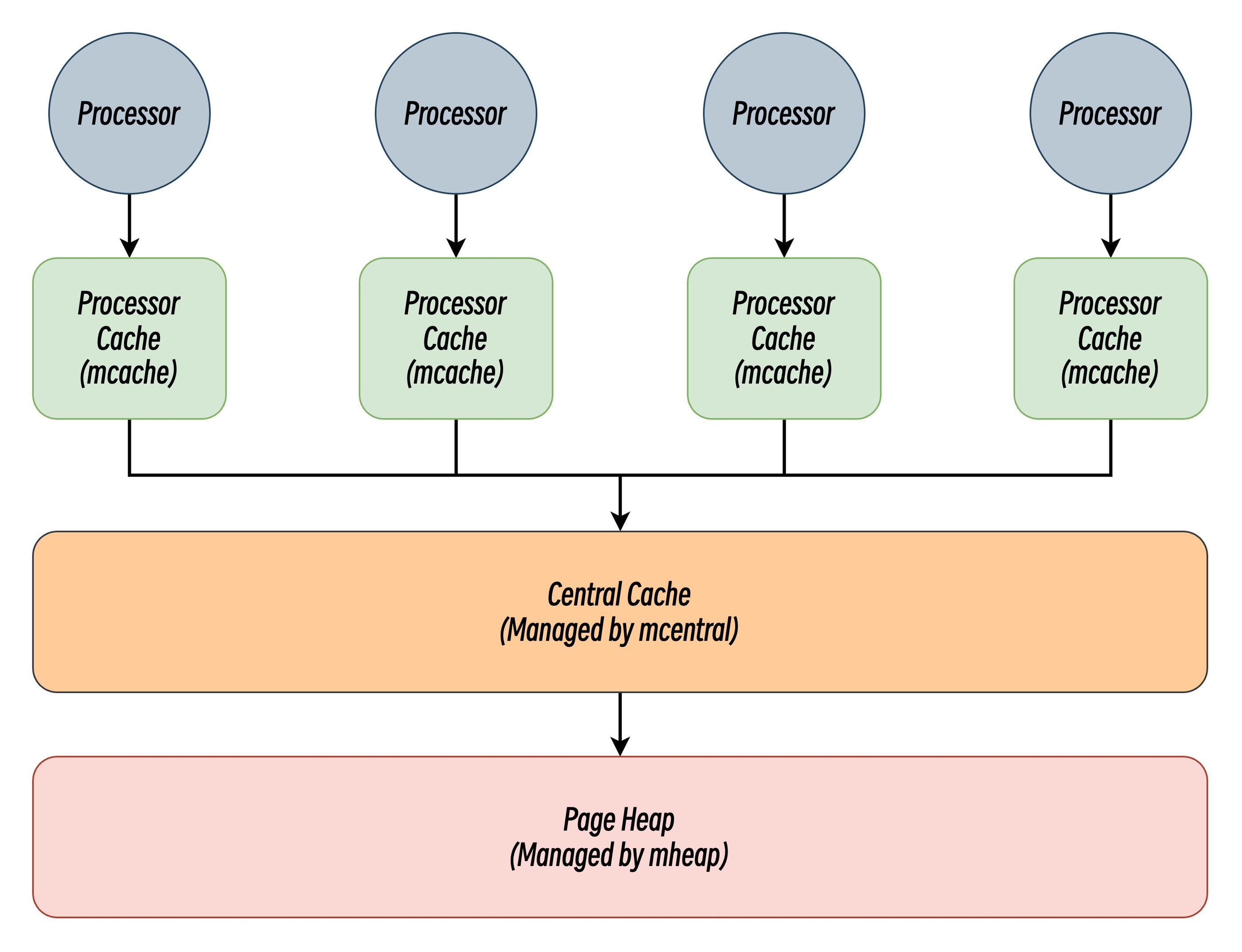
线程缓存(Per-P Cache)作为第一级缓存,能够让大多数内存分配在无锁状态下迅速完成,显著降低分配开销提高性能。这种多层级的内存分配设计与计算机操作系统中的多级缓存有些类似,因为多数的对象都是小对象,大多数情况下线程缓存(Per-P Cache)和中心缓存(Central Cache)就能提供足够的内存空间,但发现资源不足时才从上级组件中获取更多的内存。
堆虚拟内存布局
内存布局(Memory Layout) 是程序运行时各部分数据在内存中的空间分配模式和组织结构。内存布局定义了程序的各种组成部分(如代码、数据、堆、栈等)在虚拟地址空间或物理内存中的位置安排、大小分配以及相互之间的关系。
连续内存布局
在 Go 1.10 及更早版本中,运行时系统采用线性连续的内存布局策略。整个堆区虚拟地址空间被划分为三个核心区域,构成经典的三段式结构:
- Spans 区域(512MB):存储指向
runtime.mspan结构体的指针数组,每个指针对应管理 8KB 内存页。该区域作为元数据索引,建立物理页与管理单元的映射关系。通过mspan对象的链表结构,实现内存页的分配与回收追踪。 - Bitmap 区域(16GB):采用位图标记技术,每 2bit 对应 arena 区域中 8 字节内存单元。其中低位标记该地址是否包含指针,高位指示垃圾回收时是否需要继续扫描子对象。这种设计使得 GC 扫描无需遍历整个堆空间,大幅提升标记效率。
- Arena 区域(512GB):实际存储堆对象的连续地址空间,采用按页管理机制。每个
mspan管理若干连续内存页,根据对象大小划分为不同规格的存储单元。该区域通过地址连续性保证快速索引,但也因此产生 512GB 的硬性容量限制。
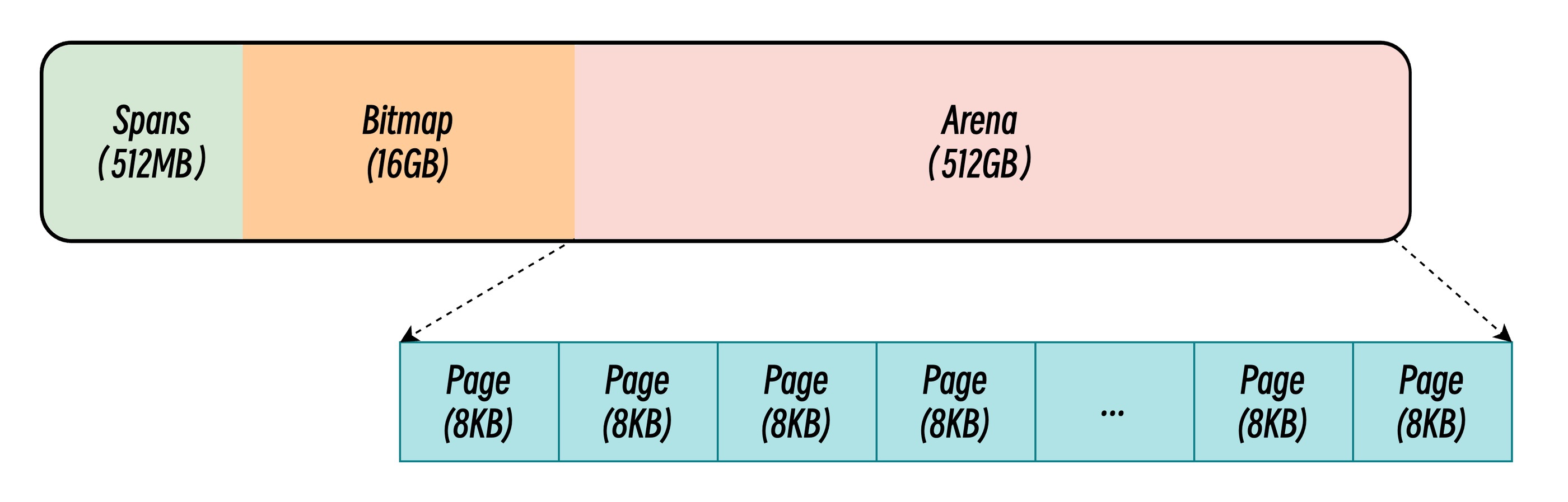
连续内存布局虽简化了内存管理逻辑,但存在显著缺陷:
- 地址空间限制:512GB 的 arena 上限无法满足大数据量应用需求,且虚拟地址预留导致实际物理内存使用效率低下。
- CGo 混合编程冲突:当 Go 程序与 C 库共享地址空间时,第三方库可能占用 arena 区域的预留地址,导致内存分配失败。这种场景在嵌入式系统和容器化部署中尤为突出。
- 内存碎片化加剧:长期运行的服务容易产生外部碎片,虽然 Go 采用复制式垃圾回收压缩内存,但连续布局限制了碎片整理策略的灵活性。导致内存利用效率低,释放的内存难以有效重用。
稀疏内存布局
Go 1.11 引入稀疏虚拟内存布局,其基本思想是将堆内存组织为非连续的内存块集合,而非单一的连续区域。
Runtime¶ The runtime now uses a sparse heap layout so there is no longer a limit to the size of the Go heap (previously, the limit was 512GiB). This also fixes rare “address space conflict” failures in mixed Go/C binaries or binaries compiled with
-race.
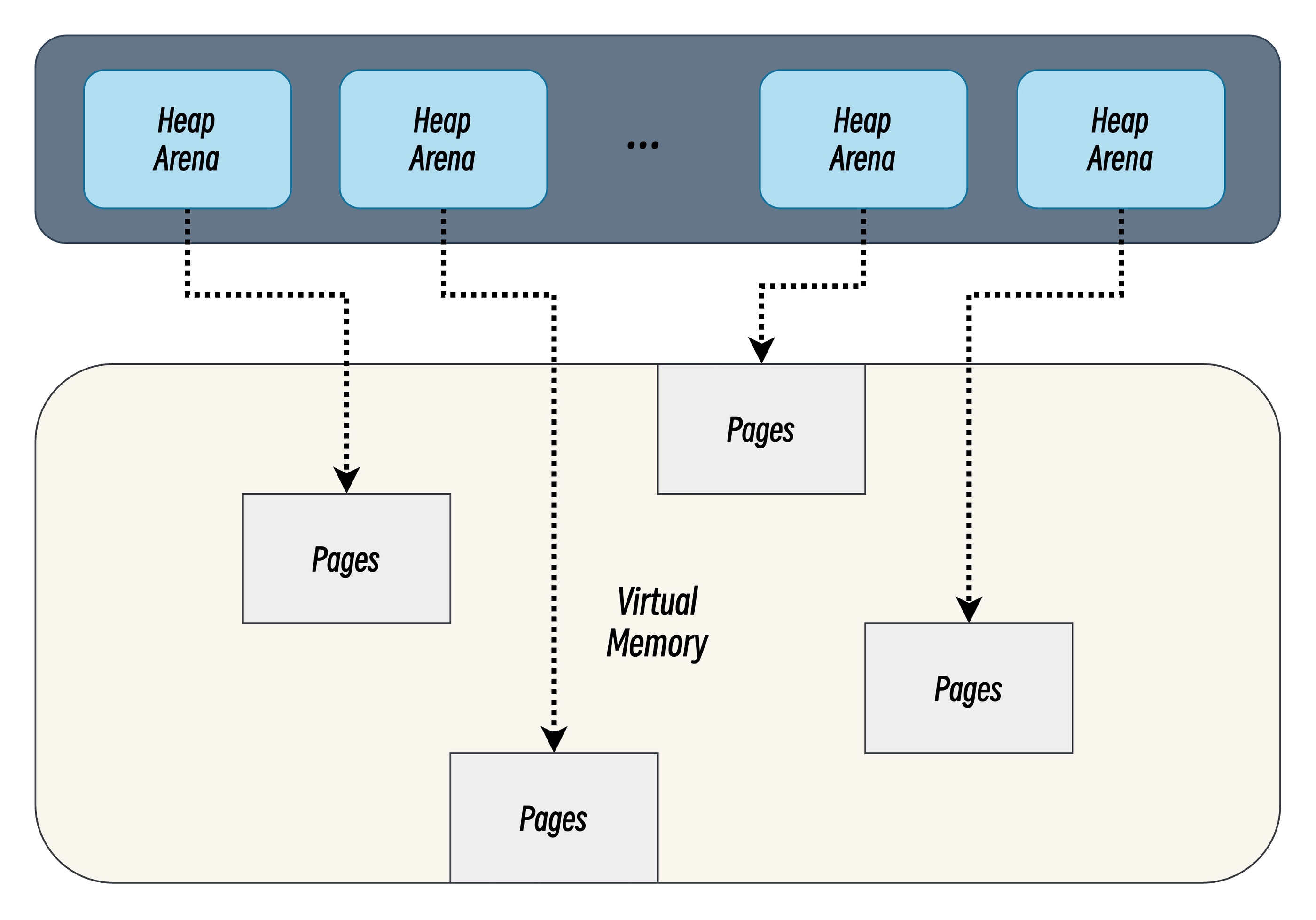
堆区的虚拟内存被划分为了一个个内存块(Arena),每个 Arena 一块固定大小的内存区域,可以独立存在,彼此之间可以不连续。同时每个 Arena 包含独立的元数据区(spans、bitmap)和对象存储区。这种设计将全局连续地址空间解耦为离散管理单元,支持按需动态扩展。此外稀疏内存布局很好地解决了上述连续内存布局的缺陷,但也引入了新的问题:
- 内存开销增加:每个 Arena 需维护各自独立的元数据,元数据总占比约 1.6%。相比连续布局的固定元数据区域,稀疏布局在内存使用效率上有所下降。
- 访问延迟变化:地址解析需要额外计算 Arena 索引,但现代 CPU 的位操作指令可将其控制在 1-2 个时钟周期内。实测显示,稀疏布局的平均分配延迟增加不超过 5%。
- GC 复杂度提升:非连续内存布局要求垃圾回收器支持跨 Arena 的对象追踪。Go 1.11 引入并优化了跨单元指针处理逻辑,使 GC 吞吐量损失控制在 1% 以内。
核心数据结构
代码分析基于: go1.24
Go 的内存分配器主要包含以下几个核心结构:
fixalloc:实现了一个自由链表(free-list)分配器,专门用于分配固定大小的对象。linearAlloc:一个基于线性分配策略的分配器。heapArena: 用于存储堆内存块元信息。mspan:表示一段相邻的、连续的内存页(由mheap分配)组成的区域。mcache:是每个 P(processor 或逻辑处理器)的私有缓存,用于小对象的快速分配和回收。mcentral:作为一个“中央调度器”,主要负责管理同一大小类别(size class)的所有mspan。mheap:是 Go 运行时中管理整个堆内存的核心组件。
fixalloc
fixalloc 是一种基于自由链表(free-list)的分配器,专门用于分配固定大小的、非堆上(off-heap)的对象。它主要用来管理内存分配器自身所需要的一些内部数据结构的存储,比如 mcache、mspan 以及其他辅助数据。在分配这些固定大小的对象时,fixalloc 通过维护一个空闲对象链表来快速复用和回收对象,避免每次都从系统中申请内存,从而提高效率。
type fixalloc struct {
size uintptr // 每个分配对象的大小(字节数)
first func(arg, p unsafe.Pointer) // 当对象首次被分配时调用的函数
arg unsafe.Pointer // 传递给 first 函数的参数
list *mlink // 指向空闲对象链表的指针,用于快速重用已释放的内存
chunk uintptr // 当前内存块的地址,使用 uintptr 而非 unsafe.Pointer 来避免 write barrier
nchunk uint32 // 当前 chunk 的剩余字节数
nalloc uint32 // 新分配内存块的大小(字节数)
inuse uintptr // 正在使用的字节数
stat *sysMemStat
zero bool // 指示分配的内存是否需要被清零
}
Go 的堆内存管理中的核心结构(span, mcache, arenaHint, specialfinalizer...)均借助 fixalloc 结构进行分配和回收。
初始化
fixalloc 作为 Go 内存分配器中的重要组成部分,为其分配的内存直接来自于操作系统,基于 Go 语言自身对零值的定义,初始化过程就是将自身的字段赋零值,确保分配器从一个明确、一致的状态开始运行。未初始化的字段可能包含随机值,这会导致不可预测的行为。
func (f *fixalloc) init(size uintptr, first func(arg, p unsafe.Pointer), arg unsafe.Pointer, stat *sysMemStat) {
// 确保请求的对象大小不超过预定义的 _FixAllocChunk 限制,否则抛出异常。
if size > __FixAllocChunk _{
throw("runtime: fixalloc size too large")
}
// 确保对象大小至少能容纳一个 mlink 结构(用于空闲列表链接)。
size = max(size, unsafe.Sizeof(mlink{}))
f.size = size
f.first = first
f.arg = arg
f.list = nil
f.chunk = 0
f.nchunk = 0
f.nalloc = uint32(__FixAllocChunk _/ size * size) // Round _FixAllocChunk down to an exact multiple of size to eliminate tail waste
f.inuse = 0
f.stat = stat
f.zero = true
}
分配
alloc 函数用于从 fixalloc 分配器中获取一个固定大小的对象。
func (f *fixalloc) alloc() unsafe.Pointer {
// 确保分配器已经被正确初始化(size > 0)
if f.size == 0 {
print("runtime: use of FixAlloc_Alloc before FixAlloc_Init\n")
throw("runtime: internal error")
}
// 尝试从空闲列表分配
if f.list != nil {
// 从列表头部获取一个对象
v := unsafe.Pointer(f.list)
// 更新空闲列表指针和已用内存计数
f.list = f.list.next
f.inuse += f.size
if f.zero {
// 对返回的内存进行清零操作
memclrNoHeapPointers(v, f.size)
}
return v
}
// 检查当前块中剩余的空间是否足够分配一个对象
if uintptr(f.nchunk) < f.size {
// 使用 persistentalloc 请求一个新的内存块,并更新相关计数器
f.chunk = uintptr(persistentalloc(uintptr(f.nalloc), 0, f.stat))
f.nchunk = f.nalloc
}
// 从新块的开始位置分配对象
v := unsafe.Pointer(f.chunk)
// 如果设置了 first 回调函数,则调用该函数
if f.first != nil {
f.first(f.arg, v)
}
// 更新块指针和计数器以反映新的分配
f.chunk = f.chunk + f.size
f.nchunk -= uint32(f.size)
f.inuse += f.size
return v
}
回收
free 函数用于将之前分配的对象返回给 fixalloc 分配器,使其可以被重用。
func (f *fixalloc) free(p unsafe.Pointer) {
f.inuse -= f.size
v := (*mlink)(p)
v.next = f.list
f.list = v
}
linearAlloc
linearAlloc 是一个简单的线性分配器,它预先保留一个内存区域,然后根据需要选择性地将该区域映射到就绪状态。
type linearAlloc struct {
next uintptr _// 下一个可用字节的地址_
mapped uintptr _// 已映射空间的末尾_
end uintptr _// 预留空间的末尾_
mapMemory bool _// 是否将内存从 Reserved 状态转换为 Ready 状态_
}
heapArenaAlloc 仅用于在 32 位操作系统下分配 heapArena 对象的预留空间,避免其内存区域和堆空间本身的内存区域交叉。
type mheap struct {
...
// heapArenaAlloc is pre-reserved space for allocating heapArena
// objects. This is only used on 32-bit, where we pre-reserve
// this space to avoid interleaving it with the heap itself.
heapArenaAlloc linearAlloc
...
}
初始化
当调用 init 函数时,实际上是在虚拟地址空间中预留了一段连续的地址范围
func (l *linearAlloc) init(base, size uintptr, mapMemory bool) {
if base+size < base {
// base + size 溢出的情况,去掉一个字节
// 保留虚拟内存预留,后续分配过程中不进行映射。
size -= 1
}
l.next, l.mapped = base, base
l.end = base + size
l.mapMemory = mapMemory
}
分配
当需要实际使用内存时,alloc 方法会在必要时将虚拟内存映射到物理内存:
func (l *linearAlloc) alloc(size, align uintptr, sysStat *sysMemStat) unsafe.Pointer {
_// 计算对齐物理内存页大小后的地址并分配_
p := alignUp(l.next, align)
if p+size > l.end {
return nil
}
l.next = p + size
if pEnd := alignUp(l.next-1, physPageSize); pEnd > l.mapped {
if l.mapMemory {
n := pEnd - l.mapped
// 将虚拟内存从"预留"状态转为"准备"状态,分配实际的页表项(但可能尚未分配物理页框)
sysMap(unsafe.Pointer(l.mapped), n, sysStat)
// 通知操作系统该内存区域即将被使用,确保分配物理内存页框
sysUsed(unsafe.Pointer(l.mapped), n, n)
}
l.mapped = pEnd
}
return unsafe.Pointer(p)
}
heapArena
type heapArena struct {
// 用于标记该结构体不应被分配在 Go 的常规堆上。这确保了垃圾回收器不会扫描或移动这些结构体。
_ sys.NotInHeap
// 这是一个指针数组,将 arena 中的每个虚拟页映射到管理该页的 mspan 结构。
// mspan 是 Go 内存管理中的另一个关键概念,它表示一组连续的页。
// - 对于已分配的 span,该 span 中的所有页都映射到这个 span 本身。
// - 对于空闲的 span,只有最低和最高的页映射到该 span 本身。
// - 中间的页可能映射到任意 span。
// - 从未分配过的页,对应的 spans 条目为 nil。
spans [_pagesPerArena_]*mspan
// 用于表示 span 处于 mSpanInUse 状态的位图
pageInUse [_pagesPerArena _/ 8]uint8
// 用于表示哪些 span 上有被标记的对象。
pageMarks [_pagesPerArena _/ 8]uint8
// 用于表示哪些 span 有特殊处理需求(如终结器 finalizer 或其他)
pageSpecials [_pagesPerArena _/ 8]uint8
// 这个字段存储了调试用的 debug.gccheckmark 状态。
// 只有在 debug.gccheckmark > 0 时才会使用。
checkmarks *checkmarksMap
// 这个字段标记了该 arena 中尚未使用且因此已经置零的第一页的第一个字节。
// zeroedBase 是相对于 arena 基址的。
zeroedBase uintptr
// src/runtime/sizeclasses.go
const (
__PageShift _= 13
)
// src/runtime/malloc.go
const (
_pageSize _= __PageSize_
__PageSize _= 1 << __PageShift_
)
// src/runtime/malloc.go
const (
// heapAddrBits 定义了 Go 运行时中堆地址位数(有效地址位的数量),用于确定内存寻址空间的大小、计算堆的内存布局和确定内存地址映射数据结构的大小和索引方式。
// 这种复杂计算的原因是不同硬件架构和操作系统对地址空间有不同的限制:
// 1. 大多数 64 位平台限制为 48 位地址(虽然地址是64位,但实际有效位只有 48 位);
// 2. iOS/ARM64特别限制为 40 位地址(历史原因和兼容性考虑,iOS14 放弃支持后提升到 48 位);
// 3. WebAssembly 有 4GB 内存限制,需要 32 位地址;
// 4. 32 位平台通常用 32 位地址;
// 5. MIPS32 只能访问低 2GB 虚拟内存,所以限制为 31 位;
// 6. Linux 虽然支持扩展到 57 位地址,但是大部分情况下都低于 48 位;
// 7. ppc64, mips64, and s390x 硬件上支持 64 位随机地址,但还是先遵循 Linux 系统的限制。
_heapAddrBits _= (__64bit_*(1-goarch._IsWasm_)*(1-goos._IsIos_*goarch._IsArm64_))*48 + (1-__64bit_+goarch._IsWasm_)*(32-(goarch._IsMips_+goarch._IsMipsle_)) + 40*goos._IsIos_*goarch._IsArm64_
// 每个 heapArena 管理的内存大小
_heapArenaBytes _= 1 << _logHeapArenaBytes_
// 是 _heapArenaBytes 的 log_2 对数_
_logHeapArenaBytes _= (6+20)*(__64bit_*(1-goos._IsWindows_)*(1-goarch._IsWasm_)*(1-goos._IsIos_*goarch._IsArm64_)) + (2+20)*(__64bit_*goos._IsWindows_) + (2+20)*(1-__64bit_) + (2+20)*goarch._IsWasm _+ (2+20)*goos._IsIos_*goarch._IsArm64_
// 每个 Arena 管理的最大页数量
_pagesPerArena _= _heapArenaBytes _/ _pageSize_
// Go 的内存管理系统采用了一个两级索引结构来映射虚拟地址到 heapArena 对象,这些常量定义了这两级索引的位数分配
// - 第一级索引表需要 PtrSize*(1<<arenaL1Bits) 大小的内存,存储在二进制文件的 BSS 段中。较小的值可以减少这种静态内存占用。
// - 每个 arena 映射表的大小与 1<<arenaL2Bits 成比例,所以这个值不宜过大。注释提到 48 位会导致 32MB 的 arena 索引分配,这已经接近实际可接受的阈值。
// - 与第一级不同,第二级索引通常是动态分配的,因此需要权衡内存使用与查找效率。
_arenaL1Bits _= 6 * (__64bit _* goos._IsWindows_)
_arenaL2Bits _= _heapAddrBits _- _logHeapArenaBytes _- _arenaL1Bits_
)
从上面的常量可以推算出不同平台下对 Arena 的管理策略不一样,虽然都是使用的二层映射机制,但不同平台下有不同取舍:
| 平台 | 内存地址位数 | logHeapArenaBytes | Arena 大小 | 一级索引表大小 | 二级索引表大小(所需内存占用,条目数 x 指针大小) |
|---|---|---|---|---|---|
| */64-bit | 48 | 26 | 64MB | 1 | 1 << 22 = 4M (32MB) |
| windows/64-bit | 48 | 22 | 4MB | 64 | 1 << 20 = 1M (8MB) |
| ios/arm64 | 40 | 22 | 4MB | 1 | 1 << 18 = 256K (2MB) |
| */32-bit | 32 | 22 | 4MB | 1 | 1 << 10 = 1024 (4KB) |
| */mips(le) | 31 | 22 | 4MB | 1 | 1 << 9 = 512 (2KB) |
arenaHint
type arenaHint struct {
_ sys.NotInHeap
// 指定一个**建议的虚拟内存起始地址**,运行时尝试从此地址开始分配新的 arena。
addr uintptr
// 指示分配内存时的**扩展方向**,控制从 addr 向高地址或低地址搜索可用空间。
// down = true:向低地址方向(内存地址递减)搜索可用区域。
// down = false:向高地址方向(内存地址递增)搜索。
down bool
// 指向链表中的下一个 arenaHint 节点,形成**单向链表**结构。
next *arenaHint
}
mspan
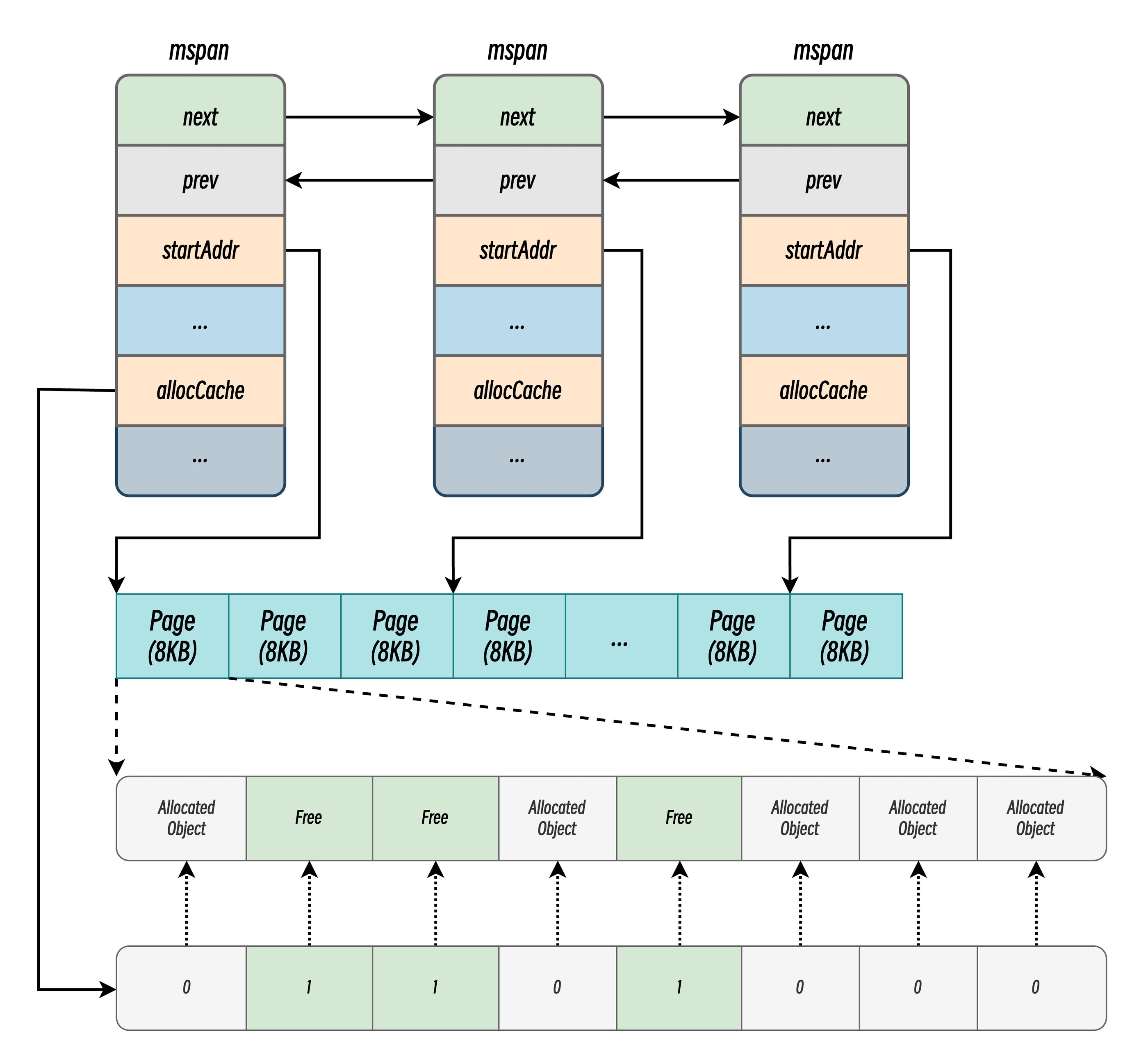
mspan 是 Go 语言堆内存管理的基本单元,用于表示一段相邻的、连续的内存页,采用双向链表连接。
内存布局和对象分配
type mspan struct {
// 用于标记该结构体不应被分配在 Go 的常规堆上。这确保了垃圾回收器不会扫描或移动这些结构体。
_ sys.NotInHeap
next *mspan // 下一个 mspan,不存在则为 nil
prev *mspan // 上一个 mspan, 不存在则为 nil
...
startAddr uintptr // 当前 mspan 内存页首字节地址
npages uintptr // 当前 mspan 管理的内存页数量
manualFreeList gclinkptr // 手动管理的空闲对象链表,用于特殊类型的 mspan(如 mSpanManual),通常与显式内存释放相关。
...
freeindex uint16 // 下一个空闲对象的索引,分配时从此处开始扫描位图。
nelems uint16 // 该 mspan 可容纳的对象总数。
freeIndexForScan uint16 // 专供垃圾回收(GC)扫描使用的起始索引,与分配器的 freeindex 隔离,避免并发冲突。
allocCache uint64 // allocBits 的缓存,通过位操作(如 ctz)快速定位空闲对象,加速分配。
allocBits *gcBits // 记录对象分配状态的位图(0 表示空闲,1 表示已分配)。
...
pinnerBits *gcBits // 记录被“固定”(不可移动)的对象,用于避免 GC 移动特定内存。
}
状态
运行时会使用 mSpanStateBox 存储 mspan 的状态:
type mSpanState uint8
const (
_mSpanDead _mSpanState = iota
_mSpanInUse _// allocated for garbage collected heap
_mSpanManual _// allocated for manual management (e.g., stack allocator)
)
type mSpanStateBox struct {
s atomic.Uint8
}
// It is nosplit to match get, below.
//go:nosplit
func (b *mSpanStateBox) set(s mSpanState) {
b.s.Store(uint8(s))
}
// It is nosplit because it's called indirectly by typedmemclr,
// which must not be preempted.
//go:nosplit
func (b *mSpanStateBox) get() mSpanState {
return mSpanState(b.s.Load())
}
type mspan struct {
...
state mSpanStateBox
...
}
该状态可能处于 mSpanDead、mSpanInUse、mSpanManual 和 mSpanFree 四种情况。当 runtime.mspan 在空闲堆中,它会处于 mSpanFree 状态;当 runtime.mspan 已经被分配时,它会处于 mSpanInUse、mSpanManual 状态,运行时会遵循下面的规则转换该状态:
- 在垃圾回收的任意阶段,可能从
mSpanFree转换到mSpanInUse和mSpanManual; - 在垃圾回收的清除阶段,可能从
mSpanInUse和mSpanManual转换到mSpanFree; - 在垃圾回收的标记阶段,不能从
mSpanInUse和mSpanManual转换到mSpanFree;
mSpanFree 状态并没有明确定义常量,后续在 mspan 操作中会提及 Go 如何界定该状态。
元信息
type mspan struct {
divMul uint32 // 预计算的乘数,用于快速将对象索引转换为内存地址(避免除法运算)。
allocCount uint16 // 已分配对象数,当等于 nelems 时,表示无空闲空间。
spanclass spanClass // 包含 sizeclass(对象大小类别)和 noscan 标记(对象是否含指针),决定 GC 是否需要扫描。
...
needzero uint8 // 分配前是否需要清零内存,确保安全性。
...
allocCountBeforeCache uint16 // a copy of allocCount that is stored just before this span is cached
elemsize uintptr // 单个对象的大小,根据 sizeclass(小微对象) 或者 npages(大对象) 计算。
limit uintptr // 当前 Span 内存块结束地址(startAddr + npages * pageSize),用于边界检查。
...
largeType *_type // 类型为 *abi.Type, 当 mspan 用于分配单个大对象时,记录其类型信息。
}
GC 相关
type mspan struct {
...
gcmarkBits *gcBits // GC 标记阶段使用的位图,标记存活对象。
...
// 清理标记,和 mheap 的 sweepgen 进行对比:
// - mspan.sweepgen == mheap.sweepgen - 2,表示需要进行清扫
// - mspan.sweepgen == mheap.sweepgen - 1, 表示正在清扫
// - mspan.sweepgen == mheap.sweepgen, 表示已清扫并就绪
// - mspan.sweepgen == mheap.sweepgen + 1, 表示 GC 开始清扫前已被缓存,需清扫
// - mspan.sweepgen == mheap.sweepgen + 3, 表示 GC 清扫后被缓存,目前仍处于缓存状态
sweepgen uint32
...
}
其他
type mspan struct {
...
isUserAreaChunk bool // 标记当前 span 是否为用户分配的特殊内存块(如 arena 模式)。
...
speciallock mutex // 互斥锁,保护 specials 和 pinnerBits 的并发修改。
specials *special // 链表,存储特殊记录(如对象析构函数、终结器)。
userArenaChunkFree addrRange // 管理用户分配内存块空闲地址范围。
}
SpanClass
SpanClass 在 Go 内存管理中的作用是对不同大小的对象进行精细化分类和管理,其设计核心在于平衡内存利用率、分配速度和管理开销。
type spanClass uint8
const (
_numSpanClasses _= __NumSizeClasses _<< 1
_tinySpanClass _= spanClass(_tinySizeClass_<<1 | 1)
)
func makeSpanClass(sizeclass uint8, noscan bool) spanClass {
return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))
}
//go:nosplit
func (sc spanClass) sizeclass() int8 {
return int8(sc >> 1)
}
//go:nosplit
func (sc spanClass) noscan() bool {
return sc&1 != 0
}
SpanClass 是 uint8 类型,其中前七位用于表示对应的 ClassID,最后一位定义为 noscan 标志,用于标记对象是否包含指针,指示垃圾回收是否需要对当前 mspan 进行 GC 扫描。
Golang 共定义了 67 种 SpanClass 以满足管理不同大小的小微对象:
表格源于 src/runtime/sizeclasses.go
| class | bytes/obj | bytes/span | objects | tail waste | max waste | min align |
|---|---|---|---|---|---|---|
| 1 | 8 | 8192 | 1024 | 0 | 87.50% | 8 |
| 2 | 16 | 8192 | 512 | 0 | 43.75% | 16 |
| 3 | 24 | 8192 | 341 | 8 | 29.24% | 8 |
| 4 | 32 | 8192 | 256 | 0 | 21.88% | 32 |
| 5 | 48 | 8192 | 170 | 32 | 31.52% | 16 |
| 6 | 64 | 8192 | 128 | 0 | 23.44% | 64 |
| ... | ... | ... | ... | ... | ... | ... |
| 66 | 28672 | 57344 | 2 | 0 | 4.91% | 4096 |
| 67 | 32768 | 32768 | 1 | 0 | 12.50% | 8192 |
- bytes/obj: 指当前 class 可容纳的最大对象大小。
- objects: 指最大可分配对象数量。
- tail waste: 每个 Span 分配完对象后剩余的无法利用的内存。
- max waste: 表示该 class 在最坏情况下的内存浪费比例。
- min align: 每个 Class 定义对象的最小对齐边界(如 8B、16B、32B),确保内存访问效率。
例如:
- Class 5
- objects = floor(8192 / 48) = 170
- tail waste = 8192 - 48 * floor(8192 / 48) = 32
- 假设所有存入 class 的对象大小为 33,根据 min align 规则,每个对象存储后都会空闲 15B,即:
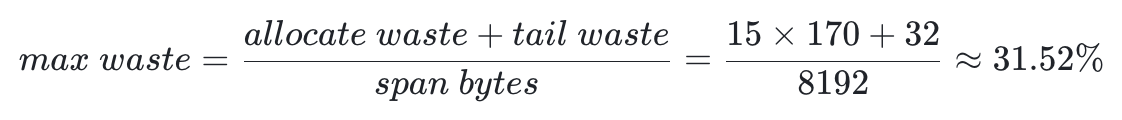
- Class 6
- objects = floor(8192 / 64) = 128
- tail waste = 8192 - 64 * floor(8192 / 64) = 0
- 假设所有存入 class 的对象大小为 49,根据 min align 规则,每个对象存储后都会空闲 15B,即:
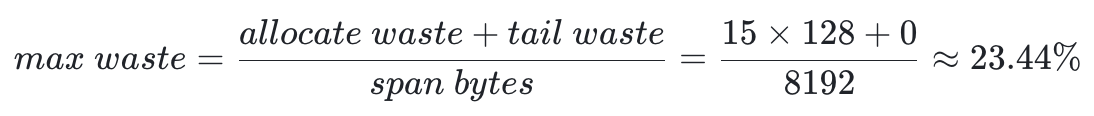
除了表格中列举的 SpanClass,运行时中还包含一个特殊的 SpanClass 0,是运行时用于管理大于 32KB 的大对象的 SpanClass,后续会在代码解析中体现。
初始化
和大多数内存管理结构一样,mspan 的初始化也是给结构中的各个变量设置初始值,起始地址和申请页数量作为入参。
func (span *mspan) init(base uintptr, npages uintptr) {
// span is *not* zeroed.
span.next = nil
span.prev = nil
span.list = nil
span.startAddr = base
span.npages = npages
span.allocCount = 0
span.spanclass = 0
span.elemsize = 0
span.speciallock.key = 0
span.specials = nil
span.needzero = 0
span.freeindex = 0
span.freeIndexForScan = 0
span.allocBits = nil
span.gcmarkBits = nil
span.pinnerBits = nil
span.state.set(_mSpanDead_)
lockInit(&span.speciallock, _lockRankMspanSpecial_)
}
mcache
type mcache struct {
_ sys.NotInHeap
nextSample int64 // 触发内存分配采样的阈值(字节数)。每次分配后递减,当值 ≤0 时触发一次内存剖析采样。
memProfRate int // 缓存当前内存剖析采样率(从全局 runtime.memProfileRate 复制而来)。
scanAlloc uintptr // 累计当前 mcache 分配的 **可扫描内存(含指针的对象)** 总量(字节数)。
tiny uintptr // 指向当前正在使用的 Tiny 内存块的起始地址。
tinyoffset uintptr // 当前 Tiny 块中已分配的偏移量(下一个可用位置的起始偏移)。
tinyAllocs uintptr // 统计当前 mcache 所属 P 通过 Tiny 分配器执行的内存分配次数。
// 按内存规格(size class)分类的 mspan 缓存数组,每个槽位对应一种大小规格。
alloc [_numSpanClasses_]*mspan
// 按栈大小分类的空闲栈内存缓存,加速 Goroutine 栈的分配/释放。
stackcache [__NumStackOrders_]stackfreelist
// 记录此 mcache 最后一次刷新时的全局 sweepgen 值。
// 若 flushGen != mheap_.sweepgen,表示缓存的 mspan 已过时,需刷新(通过 acquirep 触发)。
// 全局 sweepgen 在每次 GC 后递增,确保过期的 span 被正确回收或重新缓存。
flushGen atomic.Uint32
}
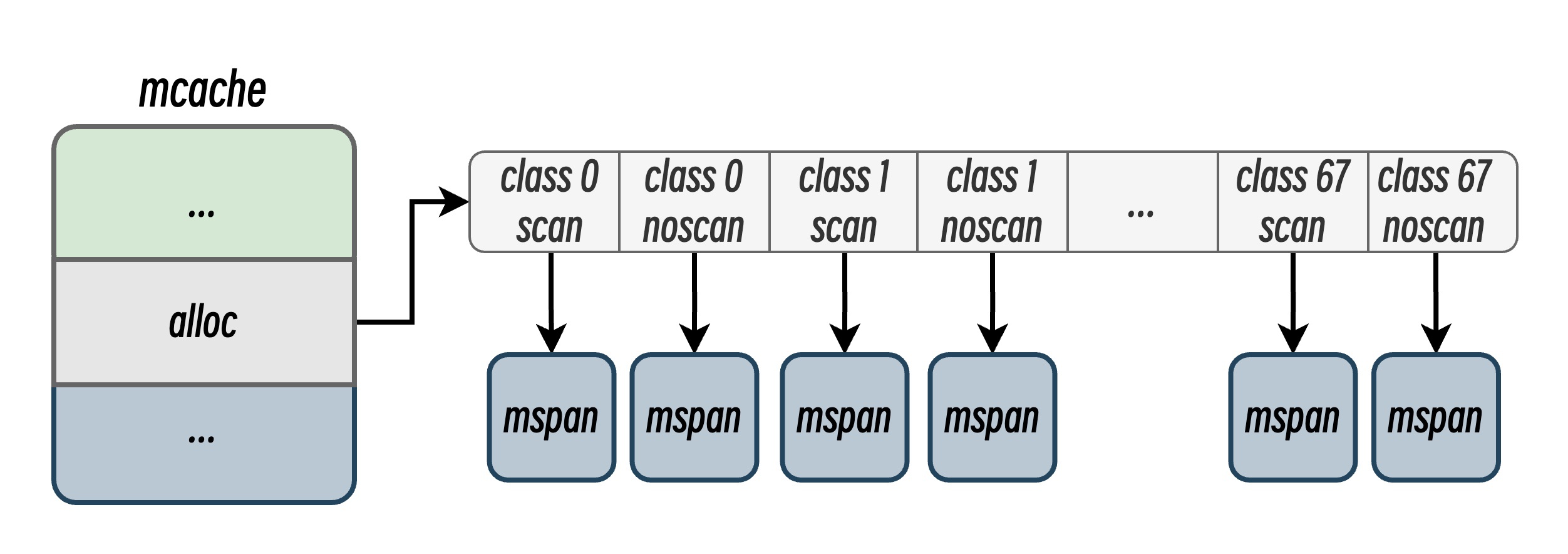
初始化分配
mcache 的初始化分配很简单,直接调用全局 mheap_.cachealloc 进行分配,其中 mheap_.cachealloc 是前文提到的 fixalloc 结构。
// dummy mspan that contains no free objects.
var emptymspan mspan
func allocmcache() *mcache {
var c *mcache
systemstack(func() {
lock(&mheap_.lock)
// 使用 fixalloc 分配一个新的 mcache
c = (*mcache)(mheap_.cachealloc.alloc())
c.flushGen.Store(mheap_.sweepgen)
unlock(&mheap_.lock)
})
for i := range c.alloc {
// 使用空 span 填充 mcache
c.alloc[i] = &emptymspan
}
c.nextSample = nextSample()
return c
}
回收
func freemcache(c *mcache) {
systemstack(func() {
// 释放所有存入 mcache 的 span
c.releaseAll()
stackcache_clear(c)
// NOTE(rsc,rlh): If gcworkbuffree comes back, we need to coordinate
// with the stealing of gcworkbufs during garbage collection to avoid
// a race where the workbuf is double-freed.
// gcworkbuffree(c.gcworkbuf)
lock(&mheap_.lock)
// 存入 cachealloc 链表中,等待下次使用
mheap_.cachealloc.free(unsafe.Pointer(c))
unlock(&mheap_.lock)
})
}
func (c *mcache) releaseAll() {
// scanAlloc 用于跟踪 GC 过程中需要扫描的存活对象内存量,重置为 0 准备下一次统计。
scanAlloc := int64(c.scanAlloc)
c.scanAlloc = 0
sg := mheap_.sweepgen
dHeapLive := int64(0)
for i := range c.alloc {
// 遍历存入的 mspan
s := c.alloc[i]
if s != &emptymspan {
// 处理非空 mspan
slotsUsed := int64(s.allocCount) - int64(s.allocCountBeforeCache)
s.allocCountBeforeCache = 0
// 统计小对象分配数据,更新内存分配总量数据
...
// 释放 mspan 到 mcentral 中央缓存
mheap_.central[i].mcentral.uncacheSpan(s)
c.alloc[i] = &emptymspan
}
}
// 清理微对象分配池
c.tiny = 0
c.tinyoffset = 0
// 统计微对象分配数据,更新堆存活内存变化量
...
}
重填充
mcache 的 refill 方法用于 在本地缓存(mcache)的某个规格(spanClass)的 span 耗尽时,从中央缓存(mcentral)获取新的 span,保证后续内存分配的快速进行。
func (c *mcache) refill(spc spanClass) {
// Return the current cached span to the central lists.
s := c.alloc[spc]
// 检查如果 mspan 还有空闲,不应该触发 refill
if s.allocCount != s.nelems {
throw("refill of span with free space remaining")
}
if s != &emptymspan {
// 确保旧 span 的 sweepgen 值为 mheap_.sweepgen + 3,
// 表示它在上一次清扫周期中被缓存,且未被异步清扫干扰。
if s.sweepgen != mheap_.sweepgen+3 {
throw("bad sweepgen in refill")
}
// 调用 uncacheSpan 将 span 归还到 mcentral
mheap_.central[spc].mcentral.uncacheSpan(s)
// 更新全局内存分配统计(如 smallAllocCount、tinyAllocCount)和
// 垃圾回收控制器(gcController)的状态,
// 确保内存管理和 GC 触发逻辑的准确性。
...
// Clear the second allocCount just to be safe.
s.allocCountBeforeCache = 0
}
// 从 mcentral 获取对应 spanClass 的仍有空闲的 mspan,
// 获取不到则证明内存已耗尽
s = mheap_.central[spc].mcentral.cacheSpan()
if s == nil {
throw("out of memory")
}
// 获取到没有空闲的 mspan,直接报错
if s.allocCount == s.nelems {
throw("span has no free space")
}
// 修改 GC 状态,指示获取到的 mspan 被缓存,避免下阶段的异步清扫
s.sweepgen = mheap_.sweepgen + 3
// **记录初始分配计数**:保存当前已分配数量(allocCountBeforeCache),供下次归还时统计实际分配量。
// **高估** heapLive:假设新 span 的所有剩余空间将被分配,提前增加 heapLive(存活堆内存量)。此高估策略避免 GC 触发过晚,导致内存占用过高
// **重置** scanAlloc:清空当前 mcache 的可扫描内存统计,为下一周期准备。
...
c.alloc[spc] = s
}
分配大对象
// allocLarge 为大对象分配 span
func (c *mcache) allocLarge(size uintptr, noscan bool) *mspan {
// 检查大小是否会溢出
if size+__PageSize _< size {
throw("out of memory")
}
// 对齐页大小,计算需要分配的页数量
npages := size >> __PageShift_
if size&__PageMask _!= 0 {
npages++
}
// Deduct credit for this span allocation and sweep if
// necessary. mHeap_Alloc will also sweep npages, so this only
// pays the debt down to npage pages.
deductSweepCredit(npages*__PageSize_, npages)
// 直接从 mheap 要求分配 npages 个页大小的内存
spc := makeSpanClass(0, noscan)
s := mheap_.alloc(npages, spc)
if s == nil {
throw("out of memory")
}
// 更新大对象分配指标,更新 GC 控制器堆内存存活指标和内存分配总量
...
// 将新分配的 mspan 存入 mcentral 的清理列表中,使后台 GC 清扫可见
mheap_.central[spc].mcentral.fullSwept(mheap_.sweepgen).push(s)
s.limit = s.base() + size
s.initHeapBits()
return s
}
mcentral
mcentral 是内存分配器的中心缓存,与 mcache 不同,访问 mcentral 中的内存 mspan 需要使用互斥锁,mcentral 是连接线程本地缓存(mcache)和全局堆(mheap)的中间层,负责管理同一规格(spanClass)的内存块(Span)的分配和回收
// src/runtime/mcentral.go
// Central list of free objects of a given size.
type mcentral struct {
_ sys.NotInHeap
spanclass spanClass // 标识当前 mcentral 管理的内存块大小类别。
// 存储**部分空闲**的 mspan,分为两个集合,用于交替处理已清扫(swept)和未清扫(unswept)的 Span。
partial [2]spanSet
// 存储**完全占用**的 mspan,同样分为两个集合,配合 GC 周期切换状态。
full [2]spanSet
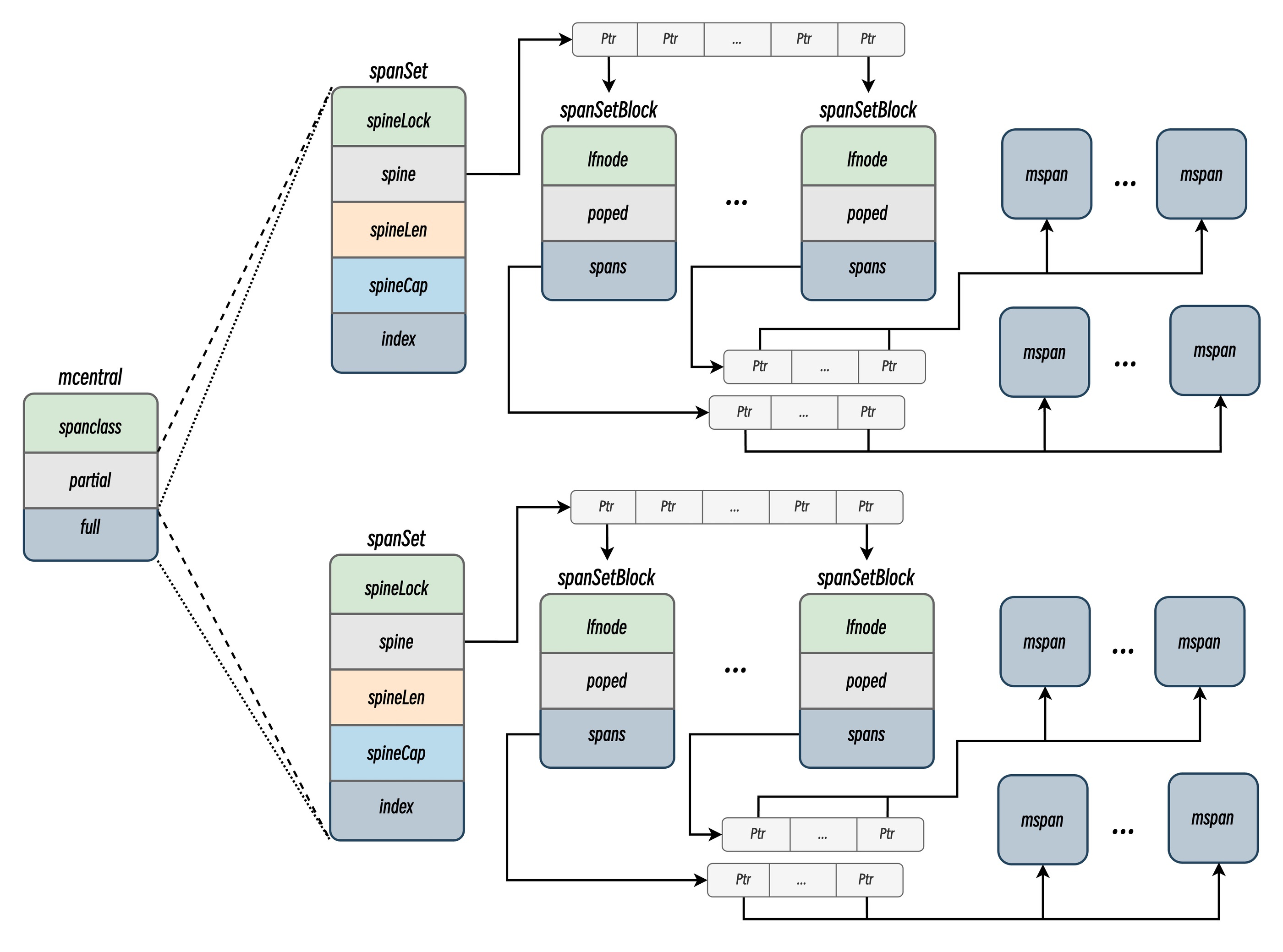
其中,partial 和 full 数组中存储的 spanSet 如下:
// src/runtime/mspanset.go
type spanSet struct {
// 互斥锁,用于保护对 spine 的修改操作(如扩容、分配新块)。
spineLock mutex
// Atomic 指针,指向 spanSetBlock 指针数组。
// 每个元素是 Atomic 指针,指向一个 spanSetBlock,通过原子操作实现无锁读取。
// *[N]atomic.Pointer[spanSetBlock]
spine atomicSpanSetSpinePointer
// 记录 spine 数组的长度
spineLen atomic.Uintptr
// 记录 spine 数组的容量
spineCap uintptr
// 基于原子操作的 64 位字段,高 32 位为 **头(head)**,
// 低 32 位为 **尾(tail)**,共同构成逻辑上的环形缓冲区索引:
// - **实现无锁队列**:支持并发环境下的高效 push 和 pop 操作。
// - **支持索引计算**:通过头尾索引映射到具体的块和位置,避免全局锁争用。
index atomicHeadTailIndex
}
初始化
mcentral 的初始化阶段主要是赋值 spanclass 和初始化 spanSet 中的互斥锁。
// Initialize a single central free list.
func (c *mcentral) init(spc spanClass) {
c.spanclass = spc
lockInit(&c.partial[0].spineLock, _lockRankSpanSetSpine_)
lockInit(&c.partial[1].spineLock, _lockRankSpanSetSpine_)
lockInit(&c.full[0].spineLock, _lockRankSpanSetSpine_)
lockInit(&c.full[1].spineLock, _lockRankSpanSetSpine_)
}
spanSet 获取
根据当前 GC 周期(sweepgen)返回对应的 spanSet。sweepgen 每次 GC 增加 2,通过 sweepgen/2%2 确定当前使用的索引(0 或 1)。partialUnswept 返回未清扫的 partial 集合,partialSwept 返回已清扫的集合。full 集合获取同理 。
// partialUnswept returns the spanSet which holds partially-filled
// unswept spans for this sweepgen.
func (c *mcentral) partialUnswept(sweepgen uint32) *spanSet {
return &c.partial[1-sweepgen/2%2]
}
// partialSwept returns the spanSet which holds partially-filled
// swept spans for this sweepgen.
func (c *mcentral) partialSwept(sweepgen uint32) *spanSet {
return &c.partial[sweepgen/2%2]
}
// fullUnswept returns the spanSet which holds unswept spans without any
// free slots for this sweepgen.
func (c *mcentral) fullUnswept(sweepgen uint32) *spanSet {
return &c.full[1-sweepgen/2%2]
}
// fullSwept returns the spanSet which holds swept spans without any
// free slots for this sweepgen.
func (c *mcentral) fullSwept(sweepgen uint32) *spanSet {
return &c.full[sweepgen/2%2]
}
获取 span
cacheSpan 是 mcentral 的核心方法,负责为线程本地缓存(mcache)分配一个包含空闲对象的 mspan。其核心逻辑是 优先复用已清扫的闲置内存块,若无法满足则触发清扫未完全占用的内存块,若再无法满足则触发清完全占用的内存块并检查是否有剩余空间后进行复用,都无法满足时则通过扩容从堆(mheap)申请新内存。整个过程平衡了内存复用效率和清扫开销。
func (c *mcentral) cacheSpan() *mspan {
// 根据申请的 span 大小扣除“清扫信用”。
// 若信用不足,触发后台清扫(Background Sweep),确保内存回收与分配平衡,避免堆积未处理垃圾
spanBytes := uintptr(class_to_allocnpages[c.spanclass.sizeclass()]) * _PageSize
deductSweepCredit(spanBytes, 0)
// ...
// 限制在寻找空闲内存时的最大清扫次数,避免因过度清扫导致延迟波动。
// 若遍历 100 个 span 仍未找到空间,直接分配新 span,以 1% 的空间开销换取稳定的吞吐量。
spanBudget := 100
var s *mspan
var sl sweepLocker
// 尝试从 partialSwept 中获取部分占用的 span
sg := mheap_.sweepgen
if s = c.partialSwept(sg).pop(); s != nil {
// 可以获取到,直接跳转至 havespan 逻辑
goto havespan
}
sl = sweep.active.begin()
if sl.valid {
// 先尝试从部分占用未清扫的 spanSet 中获取 span 进行清扫
for ; spanBudget >= 0; spanBudget-- {
s = c.partialUnswept(sg).pop()
if s == nil {
break
}
if s, ok := sl.tryAcquire(s); ok {
// 成功获取到可供复用的 span 的 所有权并进行清扫
// 因为是部分占用,确定有剩余空间,直接跳转到 havespan
s.sweep(true)
sweep.active.end(sl)
goto havespan
}
// 获取所有权失败意味着获取到的 span 可能正被异步清扫,无法从列表中移除。
// 对应的清扫方将负责将对应的 span 清扫后释放或移动到合适的列表中。
// 并发操作可能会导致系统不安全,因此这里忽略无法获取所有权的 span。
}
// 尝试从完全占用未清扫的 spanSet 中获取 span 进行清扫
for ; spanBudget >= 0; spanBudget-- {
s = c.fullUnswept(sg).pop()
if s == nil {
break
}
if s, ok := sl.tryAcquire(s); ok {
// 成功获取到可供复用的 span 的 所有权并进行清扫
s.sweep(true)
// 清扫后检查是否有腾出空间
freeIndex := s.nextFreeIndex()
if freeIndex != s.nelems {
s.freeindex = freeIndex
sweep.active.end(sl)
// 清扫后出现可用空间,直接跳转到 havespan
goto havespan
}
// 清扫后仍然没有空间,将清扫过的 span 放回到 fullSwept spanSet
c.fullSwept(sg).push(s.mspan)
}
}
sweep.active.end(sl)
}
// ...
// 上述流程都失败,为了避免过度提高延迟,直接通过 mheap 分配新的 span
s = c.grow()
if s == nil {
return nil
}
havespan:
...
n := int(s.nelems) - int(s.allocCount)
// 检查获取到的 span, 不应该处于满载状态
if n == 0 || s.freeindex == s.nelems || s.allocCount == s.nelems {
throw("span has no free objects")
}
freeByteBase := s.freeindex &^ (64 - 1)
whichByte := freeByteBase / 8
_// 重置分配位图缓存_
s.refillAllocCache(whichByte)
_// 对齐空闲位_
s.allocCache >>= s.freeindex % 64
return s
}
释放 span
// 从 mcache 释放 span 到 mcentral
func (c *mcentral) uncacheSpan(s *mspan) {
// 不应该释放空的 span 到 mcentral
if s.allocCount == 0 {
throw("uncaching span but s.allocCount == 0")
}
// 判断 span 清扫状态
sg := mheap_.sweepgen
stale := s.sweepgen == sg+1
// 若 Span 在缓存期间未被清扫(stale),则主动触发清扫。
if stale {
// span 在清扫前已经 cache,需要进行一次清扫
_// 标记为待清扫_
atomic.Store(&s.sweepgen, sg-1)
} else {
// 已清扫过,_标记已同步当前周期,不在 cache 状态_
atomic.Store(&s.sweepgen, sg)
}
if stale {
// 直接进行清扫工作:
// sweepLocked 绕过常规的 sweepLocker 锁机制,因为 stale 的 span 不在全局清扫队列。
ss := sweepLocked{s}
ss.sweep(false)
} else {
if int(s.nelems)-int(s.allocCount) > 0 {
// 无需清扫的空闲 span 放入 partialSwept 集合
c.partialSwept(sg).push(s)
} else {
// 无需清扫的满载 span 放入 fullSwept 集合
c.fullSwept(sg).push(s)
}
}
}
下列函数对需要被释放到 mcentral 的待清扫 span 进行清扫和最终处理,主要关注 span 的最终归属,对 span 的清扫细节不进行细致分析。
func (sl *sweepLocked) sweep(preserve bool) bool {
// 对需要清扫的 span 进行清扫操作
...
// 用户分配的 span
if s.isUserArenaChunk {
...
if nalloc > 0 {
// 对非空闲的 span 放入 fullSwept spanSet,等待下次 GC。
mheap_.central[spc].mcentral.fullSwept(sweepgen).push(s)
return false
}
// 完全空闲的 span 则标记为 mSpanDead 状态
mheap_.pagesInUse.Add(-s.npages)
s.state.set(mSpanDead)
// 移入 mheap.userArena.readyList 等待重用
systemstack(func() {
if s.list != &mheap_.userArena.quarantineList {
throw("user arena span is on the wrong list")
}
lock(&mheap_.lock)
mheap_.userArena.quarantineList.remove(s)
mheap_.userArena.readyList.insert(s)
unlock(&mheap_.lock)
})
return false
}
// 处理小对象 span
if spc.sizeclass() != 0 {
...
if !preserve {
// 清扫之后完全空闲
if nalloc == 0 {
// 直接归还到堆
mheap_.freeSpan(s)
return true
}
// 清扫之后仍有占用,插入 mcentral 已清扫 spanSet
if nalloc == s.nelems {
// 完全占用
mheap_.central[spc].mcentral.fullSwept(sweepgen).push(s)
} else {
// 部分占用
mheap_.central[spc].mcentral.partialSwept(sweepgen).push(s)
}
}
} else if !preserve {
// sizeclass == 0 存储超大对象,其管理方式稍有不同
// 一般来说超大对象是专门分配的空间,nfreed != 0 说明已释放对象
if nfreed != 0 {
...
if debug.efence > 0 {
s.limit = 0 // prevent mlookup from finding this span
sysFault(unsafe.Pointer(s.base()), size)
} else {
// 调用 freeSpan 归还堆
mheap_.freeSpan(s)
}
return true
}
// 放入 fullSwept 列表,等待后续处理
mheap_.central[spc].mcentral.fullSwept(sweepgen).push(s)
}
return false
}
分配 span
在获取 span 操作中,如果经过多次遍历 spanSet 和尝试清扫都没有寻找到可复用的内存块,就会调用下列函数申请内存分配新 span。
func (c *mcentral) grow() *mspan {
// 计算需要的页面数(npages)和对象大小(size)。
npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()])
size := uintptr(class_to_size[c.spanclass.sizeclass()])
// 调用 mheap_.alloc 分配 Span
s := mheap_.alloc(npages, c.spanclass)
if s == nil {
return nil
}
// 初始化 span 元数据(如 limit 和堆位图)。
n := s.divideByElemSize(npages << __PageShift_)
s.limit = s.base() + size*n
s.initHeapBits()
return s
}
mheap
Mheap 是 Go 内存管理的最核心组件,是 Go 语言运行时系统的全局堆管理器,负责虚拟地址空间划分、物理内存页分配、垃圾回收(GC)协作等核心功能。其设计目标是高效管理内存分配与回收,同时支持高并发场景。
基础控制字段
type mheap struct {
// 确保 mheap 本身不在 Go 堆上分配,避免循环依赖
_ sys.NotInHeap
// 全局堆锁,保护 mheap 的并发访问。
// 只能在系统栈上获取,防止栈增长时的死锁。
lock mutex
}
核心管理字段
// src/runtime/mehap.go
type mheap struct {
// 物理内存页分配器,管理页的分配与释放。
// 通过位图跟踪页状态,支持快速查找连续空闲页。
pages pageAlloc
// 清扫代计数器,用于标记 mspan 的清扫状态。每次 GC 后递增。
// mspan.sweepgen 与 mheap.sweepgen 的差值决定其清扫状态。
sweepgen uint32
// 全局所有 mspan 的列表,用于遍历所有内存块。
// 需手动管理内存,避免 GC 干扰。
allspans []*mspan
}
GC 协助清扫字段
// src/runtime/mehap.go
type mheap struct {
// 当前使用中的页数,反映堆的活跃内存。
pagesInUse atomic.Uintptr
// 当前周期已清扫页数。
pagesSwept atomic.Uint64
// 基准清扫页数,记录某一时刻(如 GC 周期开始时)已清扫的物理内存页数,
// 作为后续计算清扫进度的**起点**。
pagesSweptBasis atomic.Uint64
// 基准堆活跃内存,记录同一时刻堆中存活对象占用的内存总量(gcController.heapLive),
// 作为计算当前内存需求的**基准值**。
sweepHeapLiveBasis uint64
// 动态调整的清扫速率,根据堆使用情况(gcController.heapLive)计算需清扫的页数,
// 确保内存释放与分配平衡。
sweepPagesPerByte float64
}
页回收字段
// src/runtime/mehap.go
type mheap struct {
// 下一个待回收页的索引,按顺序扫描所有页。
// 给定 reclaimIndex = i
// 则 arenaIdx = i / pagesPerArena
// 则 pageIdx = i % pagesPerArena
// 同时 arena = mheap.allArenas[i/pagesPerArena]
// 如果 reclaimIndex >= 1<<63,这证明已完成全部扫描
reclaimIndex atomic.Uint64
// 超额回收的页数,用于后续分配前请求,减少频繁回收。
reclaimCredit atomic.Uintptr
}
Arena 管理字段
// src/runtime/mehap.go
mheap struct {
// 二级映射表,管理虚拟地址空间到 heapArena 的映射。
// 映射逻辑参考 heapArena
arenas [1 << _arenaL1Bits_]*[1 << _arenaL2Bits_]*heapArena
// 标识 L2 条目是否可以使用大页面
arenasHugePages bool
// 预分配的 heapArena 对象空间(主要用于 32 位系统)
heapArenaAlloc linearAlloc
// 存储**潜在可用内存区域的地址提示**,
// 用于指导运行时在虚拟地址空间中高效分配新的 Arena。
arenaHints *arenaHint
// 预分配的 arena 空间(仅用于 32 位系统)
arena linearAlloc
_// 所有已分配的 heapArena 索引列表_
allArenas []arenaIdx
_// GC 清扫阶段开始时的 arena 快照_
sweepArenas []arenaIdx
_// GC 标记阶段开始时的 arena 快照_
markArenas []arenaIdx
// 记录堆扩展的当前 Arena,确保地址连续和对齐,优化内存布局。
curArena struct {
base, end uintptr
}
}
中心缓存管理字段
// src/runtime/mehap.go
type mheap struct {
// 按 spanClass 分类的中央缓存,管理不同大小类的小对象内存块。
// 每个 mcentral 分为部分清扫(Partial)和完全清扫(Full)列表。
// 详细介绍参考 mcentral
central [_numSpanClasses_]struct {
mcentral mcentral
// 缓存行填充,避免伪共享(False Sharing),提升多核并发性能。
pad [(cpu._CacheLinePadSize _- unsafe.Sizeof(mcentral{})%cpu._CacheLinePadSize_) % cpu._CacheLinePadSize_]byte
}
}
分配器相关字段
// src/runtime/mehap.go
type mheap struct {
// fixalloc 为固定大小结构链表分配器,参考 fixalloc
spanalloc fixalloc // mspan 分配器
cachealloc fixalloc // mcache 分配器
specialfinalizeralloc fixalloc // specialfinalizer 分配器
specialCleanupAlloc fixalloc // specialcleanup 分配器
specialprofilealloc fixalloc // pecialprofile 分配器
specialReachableAlloc fixalloc // specialReachable 分配器
specialPinCounterAlloc fixalloc // specialPinCounter 分配器
specialWeakHandleAlloc fixalloc // specialWeakHandle 分配器
speciallock mutex // special 记录锁,用于控制 mheap 中 special 相关链表的并发访问
arenaHintAlloc fixalloc // arenaHints 分配器
}
UserArena 相关字段
// src/runtime/mehap.go
type mheap struct {
userArena struct {
// 存储**潜在可用内存区域的地址提示**,
// 用于指导运行时在虚拟地址空间中高效分配新的 User Arena。
arenaHints *arenaHint
// 隔离待回收的 Arena,确保无残留指针后移至 readyList 重用。
quarantineList mSpanList
// UserArena 中可重用 span 列表
readyList mSpanList
}
}
其他字段
// src/runtime/mehap.go
type mheap struct {
// specialCleanup 全局计数器
cleanupID uint64
// 未使用字段
// 作用是强制将 specialfinalizer 类型信息包含在 DWARF 调试信息中
unused *specialfinalizer
}
初始化
// src/runtime/mehap.go
func (h *mheap) init() {
//初始化互斥锁
lockInit(&h.lock, _lockRankMheap_)
lockInit(&h.speciallock, _lockRankMheapSpecial_)
// 初始化链表分配器
h.spanalloc.init(unsafe.Sizeof(mspan{}), recordspan, unsafe.Pointer(h), &memstats.mspan_sys)
h.cachealloc.init(unsafe.Sizeof(mcache{}), nil, nil, &memstats.mcache_sys)
h.specialfinalizeralloc.init(unsafe.Sizeof(specialfinalizer{}), nil, nil, &memstats.other_sys)
h.specialCleanupAlloc.init(unsafe.Sizeof(specialCleanup{}), nil, nil, &memstats.other_sys)
h.specialprofilealloc.init(unsafe.Sizeof(specialprofile{}), nil, nil, &memstats.other_sys)
h.specialReachableAlloc.init(unsafe.Sizeof(specialReachable{}), nil, nil, &memstats.other_sys)
h.specialPinCounterAlloc.init(unsafe.Sizeof(specialPinCounter{}), nil, nil, &memstats.other_sys)
h.specialWeakHandleAlloc.init(unsafe.Sizeof(specialWeakHandle{}), nil, nil, &memstats.gcMiscSys)
h.arenaHintAlloc.init(unsafe.Sizeof(arenaHint{}), nil, nil, &memstats.other_sys)
// 后台垃圾回收(GC)的清扫(sweeping)操作可能并发访问 mspan。
// 若分配时清零 mspan,其 sweepgen 字段可能被错误重置为 0,导致 GC 竞争问题。
// 同时 mspan 不包含堆指针,无需清零即可复用内存。
h.spanalloc.zero = false
// 初始化 mcentral
for i := range h.central {
h.central[i].mcentral.init(spanClass(i))
}
h.pages.init(&h.lock, &memstats.gcMiscSys, false)
}
回收内存
在 Go 运行时堆(mheap)中回收指定数量(npage)的物理内存页,供后续重新分配。核心目标是在垃圾回收(GC)后释放空闲内存,减少内存占用。并通过分块处理和信用机制优化回收性能,降低锁竞争。
// src/runtime/mehap.go
func (h *mheap) reclaim(npage uintptr) {
// reclaimIndex 标记当前回收进度,当其达到最大值(1<<63)时,
// 表示所有可回收区域已处理完毕,直接返回。
if h.reclaimIndex.Load() >= 1<<63 {
return
}
mp := acquirem()
...
_// 待回收的内存区域集合_
arenas := h.sweepArenas
locked := false
for npage > 0 {
_// 优先使用信用额度(复用之前超额回收的页面)_
if credit := h.reclaimCredit.Load(); credit > 0 {
take := credit
if take > npage {
// 仅获取所需额度即可
take = npage
}
if h.reclaimCredit.CompareAndSwap(credit, credit-take) {
npage -= take
}
// 跳出检查是否需要更多的页面
continue
}
// 获取待回收页 index
// Add(512) 原子性地将 reclaimIndex 增加 512
// 再减去 512 得到**本次处理的起始索引**
// 这样每个 goroutine 都能获得独占的 512 个页面来处理回收
idx := uintptr(h.reclaimIndex.Add(pagesPerReclaimerChunk) - pagesPerReclaimerChunk)
if idx/pagesPerArena >= uintptr(len(arenas)) {
// 如果计算得出 arena 的 index 超出总长度,
// 则证明没有可回收页面,直接跳出
h.reclaimIndex.Store(1 << 63)
break
}
// 锁定堆并开始回收
if !locked {
lock(&h.lock)
locked = true
}
// 扫描 arena 中的页,并尝试回收空闲页
nfound := h.reclaimChunk(arenas, idx, pagesPerReclaimerChunk)
if nfound <= npage {
// 还在需求范围内,直接扣减所需页面
npage -= nfound
} else {
// 超额回收,完成任务同时,增加超额回收额度
h.reclaimCredit.Add(nfound - npage)
npage = 0
}
}
if locked {
unlock(&h.lock)
}
...
releasem(mp)
}
// src/runtime/mehap.go
func (h *mheap) reclaimChunk(arenas []arenaIdx, pageIdx, n uintptr) uintptr {
// 由于 span 可能会被并发清扫和合并,导致访问到错误的指针。
// 确认获取到锁保证数据一致性,防止并发操作导致的问题。
assertLockHeld(&h.lock)
n0 := n
var nFreed uintptr
sl := sweep.active.begin()
if !sl.valid {
return 0
}
for n > 0 {
// 确认 arenaIdx
ai := arenas[pageIdx/pagesPerArena]
ha := h.arenas[ai.l1()][ai.l2()]
// 获取 pageIdx
arenaPage := uint(pageIdx % pagesPerArena)
_// 确认使用和 GC 标记状态_
inUse := ha.pageInUse[arenaPage/8:]
marked := ha.pageMarks[arenaPage/8:]
// 超出扫描范围,缩减右边界
if uintptr(len(inUse)) > n/8 {
inUse = inUse[:n/8]
marked = marked[:n/8]
}
for i := range inUse {
_// 找到正在使用但未被标记的页面_
inUseUnmarked := atomic.Load8(&inUse[i]) &^ marked[i]
if inUseUnmarked == 0 {
// 当前页不符合条件,跳过
continue
}
for j := uint(0); j < 8; j++ {
if inUseUnmarked&(1<<j) != 0 {
// 找到可回收的页面
s := ha.spans[arenaPage+uint(i)*8+j]
if s, ok := sl.tryAcquire(s); ok {
// 获取所有权并进行清扫
npages := s.npages
// 在清扫期间释放锁,避免长时间持锁
unlock(&h.lock)
if s.sweep(false) {
nFreed += npages
}
lock(&h.lock)
_// 重新加载位图,因为释放锁期间可能有变化_
inUseUnmarked = atomic.Load8(&inUse[i]) &^ marked[i]
}
}
}
}
_// 推进到下一个块_
pageIdx += uintptr(len(inUse) * 8)
n -= uintptr(len(inUse) * 8)
}
sweep.active.end(sl)
...
assertLockHeld(&h.lock) // Must be locked on return.
return nFreed
}
inUse &^ marked = inUse AND (NOT marked)
页面状态示例 (每位代表一个页面):
inUse: 11110110 (页面 0,1,2,3,5,6 正在使用)
marked: 10100100 (页面 0,2,5 被标记为存活)
inUseUnmarked = inUse &^ marked = 01010010
↑ ↑ ↑
页面1,3,6 可以回收
还有一点题外话,我们在 mheap 相关操作中之发现将 reclaimIndex 设置为完成扫描,没有启动下一次扫描的操作,这个变量的重置实际上是在 GC 清扫阶段操作的。
// src/runtime/mgc.go
func gcSweep(mode gcMode) bool {
...
lock(&mheap_.lock)
mheap_.sweepgen += 2
sweep.active.reset()
mheap_.pagesSwept.Store(0)
mheap_.sweepArenas = mheap_.allArenas
mheap_.reclaimIndex.Store(0)
mheap_.reclaimCredit.Store(0)
unlock(&mheap_.lock)
...
}
分配 mspan
alloc 函数 负责从堆(heap)中分配指定页数和 spanclass 的内存段(span)
func (h *mheap) alloc(npages uintptr, spanclass spanClass) *mspan {
// 防止在Goroutine栈上执行堆锁定操作时,
// 因栈扩展(需要堆内存)导致死锁。
var s *mspan
systemstack(func() {
// 防止堆内存过度增长,检查垃圾回收的清扫(sweep)阶段是否完成。
// 如果未完成,调用 reclaim 尝试回收至少 ** npages ** 页的内存。
if !isSweepDone() {
h.reclaim(npages)
}
s = h.allocSpan(npages, _spanAllocHeap_, spanclass)
})
return s
}
// src/runtime/mpagecache.go
const _pageCachePages _= 8 * unsafe.Sizeof(pageCache{}.cache)
// src/runtime/mheap.go
//go:systemstack
func (h *mheap) allocSpan(npages uintptr, typ spanAllocType, spanclass spanClass) (s *mspan) {
...
// 部分平台需要物理对齐内存页,先确认是否需要对齐
needPhysPageAlign := physPageAlignedStacks && typ == spanAllocStack && pageSize < physPageSize
pp := gp.m.p.ptr()
// 快速无锁分配路径,但需要符合以下条件
// 1. 无需对齐物理内存页
// 2. 所分配页数小于 16 页
if !needPhysPageAlign && pp != nil && npages < pageCachePages/4 {
c := &pp.pcache
// 分配 span 填充 Pre-Thread Cache
if c.empty() {
lock(&h.lock)
*c = h.pages.allocToCache()
unlock(&h.lock)
}
// 再从 cache 中获取所需内存页
base, scav = c.alloc(npages)
if base != 0 {
s = h.tryAllocMSpan()
if s != nil {
goto HaveSpan
}
}
}
// 加锁流程
lock(&h.lock)
if needPhysPageAlign {
// 需要物理页对齐
// 计算需要多分配的物理页以达到对齐目的
extraPages := physPageSize / pageSize
// 找到足够大的空间进行分配
base, _ = h.pages.find(npages + extraPages)
if base == 0 {
var ok bool
// 没有找到符合条件的区域
// 扩展堆空间
growth, ok = h.grow(npages + extraPages)
if !ok {
unlock(&h.lock)
return nil
}
// 扩展堆内存之后再次尝试分配
base, _ = h.pages.find(npages + extraPages)
if base == 0 {
throw("grew heap, but no adequate free space found")
}
}
// 对齐内存
base = alignUp(base, physPageSize)
scav = h.pages.allocRange(base, npages)
}
if base == 0 {
// 尝试分配所需内存页
base, scav = h.pages.alloc(npages)
if base == 0 {
// 没有找到符合条件的区域
// 扩展堆空间
var ok bool
growth, ok = h.grow(npages)
if !ok {
unlock(&h.lock)
return nil
}
// 扩展堆内存之后再次尝试分配
base, scav = h.pages.alloc(npages)
if base == 0 {
throw("grew heap, but no adequate free space found")
}
}
}
if s == nil {
// 通过 heap.spanalloc 重新分配一个 mspan
s = h.allocMSpanLocked()
}
unlock(&h.lock)
HaveSpan:
...
// 初始化 mspan
h.initSpan(s, typ, spanclass, base, npages)
}
allocSpan 根据不同情况从 pageCache.alloc 中获取可复用的页或者调用 pageAlloc.alloc 分配新页:
- 如果申请的内存比较小,则尝试调用
pageCache.alloc获取可复用内存区域的基地址和大小; - 如果申请的内存比较大或者线程的页缓存中内存不足,则通过
pageAlloc.alloc在页堆上申请内存; - 如果发现页堆上的内存不足,会尝试通过
mheap.grow扩容并重新调用pageAlloc.alloc申请内存:- 如果申请到内存,意味着扩容成功;
- 如果没有申请到内存则扩容失败,证明无法申请到可用的内存;
除了分配所需的内存页和 mspan 之外,allocSpan 函数还有一些辅助内存回收的逻辑。
// src/runtime/mheap.go
//go:systemstack
func (h *mheap) allocSpan(npages uintptr, typ spanAllocType, spanclass spanClass) (s *mspan) {
...
HaveSpan:
// 在分配过程中尝试回收内存
// 优先释放碎片化内存,减轻后续分配压力。
bytesToScavenge := uintptr(0)
forceScavenge := false
// 启用了 GOMEMLIMIT 且总内存超限。
if limit := gcController.memoryLimit.Load(); !gcCPULimiter.limiting() {
inuse := gcController.mappedReady.Load()
// 计算所需回收量,并标记为需要强制回收
if uint64(scav)+inuse > uint64(limit) {
bytesToScavenge = uintptr(uint64(scav) + inuse - uint64(limit))
forceScavenge = true
}
}
// 堆增长 超过 GC 目标(GOGC 百分比)
// 即当当前保留内存 + 堆增长量 > GOGC目标值(如100%增长)时触发
if goal := scavenge.gcPercentGoal.Load(); goal != ^uint64(0) && growth > 0 {
if retained := heapRetained(); retained+uint64(growth) > goal {
// 需回收量 = 堆增长量 或 超出目标值部分
todo := growth
if overage := uintptr(retained + uint64(growth) - goal); todo > overage {
todo = overage
}
// 和先前计算的内存超限需求取最大值比对
// 优先选择其中较大值,处理更紧急的需求
if todo > bytesToScavenge {
bytesToScavenge = todo
}
}
}
var now int64
if pp != nil && bytesToScavenge > 0 {
start := nanotime()
_// 启动CPU限流监测 (防止回收影响程序性能)_
track := pp.limiterEvent.start(limiterEventScavengeAssist, start)
_// 执行实际回收 (核心操作)_
released := h.pages.scavenge(bytesToScavenge, func() bool {
return gcCPULimiter.limiting() _// 监测回调:若CPU限流则中断回收_
}, forceScavenge)
_// 更新全局回收统计_
mheap_.pages.scav.releasedEager.Add(released)
_// 结束耗时统计_
now = nanotime()
if track {
// 停止_CPU限流监测_
pp.limiterEvent.stop(limiterEventScavengeAssist, now)
}
scavenge.assistTime.Add(now - start)
}
...
}
堆扩容
func (h *mheap) grow(npage uintptr) (uintptr, bool) {
assertLockHeld(&h.lock)
// 向上对齐分配内存页数量到 pallocChunkPages 的整数倍
// pallocChunkPages(通常是 512 页 = 4MB)
ask := alignUp(npage, pallocChunkPages) * pageSize
totalGrowth := uintptr(0)
// 计算内存地址,对齐物理内存页
end := h.curArena.base + ask
nBase := alignUp(end, physPageSize)
// _检查当前 arena 是否有足够空间_
if nBase > h.curArena.end || /* overflow */ end < h.curArena.base {
_// 空间不足溢出,尝试分配新空间_
_// 通过 sysAlloc 申请新内存块_
av, asize := h.sysAlloc(ask, &h.arenaHints, true)
if av == nil {
_// 物理内存不足导致 OOM_
inUse := gcController.heapFree.load() + gcController.heapReleased.load() + gcController.heapInUse.load()
print("runtime: out of memory: cannot allocate ", ask, "-byte block (", inUse, " in use)\n")
return 0, false
}
_// 新分配的内存区域和原有内存区域的连续性检查_
if uintptr(av) == h.curArena.end {
// 新旧空间连续,直接延长当前 Arena
h.curArena.end = uintptr(av) + asize
} else {
// 新旧空间不连续(比较罕见),需要进行新旧空间切换
if size := h.curArena.end - h.curArena.base; size != 0 {
// 原有 Arena 仍有剩余空间,将剩余空间切换为可用状态
sysMap(unsafe.Pointer(h.curArena.base), size, &gcController.heapReleased)
...
// 将原有空间提交回到 pageAlloc,给后续重新分配
h.pages.grow(h.curArena.base, size)
totalGrowth += size
}
// 切换到新的空间
h.curArena.base = uintptr(av)
h.curArena.end = uintptr(av) + asize
}
// 重新计算当前区域基地址
nBase = alignUp(h.curArena.base+ask, physPageSize)
}
// 更新基地址
v := h.curArena.base
h.curArena.base = nBase
// 将内存区域状态从 Reserved 转换为 Prepared
sysMap(unsafe.Pointer(v), nBase-v, &gcController.heapReleased)
...
// 将新内存区域纳入页分配器管理
h.pages.grow(v, nBase-v)
totalGrowth += nBase - v
return totalGrowth, true
}
mheap.grow 会向操作系统申请更多的内存空间,传入的页数经过对齐可以得到期望的内存大小,我们可以将该方法的执行过程分成以下几个部分:
- 通过传入的页数获取期望分配的内存空间大小以及内存的基地址;
- 如果
arena区域没有足够的空间,调用mheap.sysAlloc从操作系统中申请更多的内存; - 扩容
mheap持有的arena区域并更新页分配器的元信息; - 在某些场景下,调用
pageAlloc.scavenge回收不再使用的空闲内存页;
在页堆扩容的过程中,mheap.sysAlloc 是页堆用来申请虚拟内存的方法,我们会分几部分介绍该方法的实现。首先,该方法会尝试在预保留的区域申请内存(针对 32 位操作系统的优化):
func (h *mheap) sysAlloc(n uintptr, hintList **arenaHint, register bool) (v unsafe.Pointer, size uintptr) {
assertLockHeld(&h.lock)
n = alignUp(n, heapArenaBytes)
// 针对 32 位操作系统的优化,使用 arena 线性分配内存
// 判断是否为堆扩容,优先使用预留的地址空间;
// 减少内存碎片,降低堆扩容开销;
// 同时避免其他类型的内存分配误用预留地址空间。
if hintList == &h.arenaHints {
// 优先使用 h.arena 预先保留的地址空间进行分配
v = h.arena.alloc(n, heapArenaBytes, &gcController.heapReleased)
if v != nil {
size = n
goto mapped
}
}
...
}
如果预留的空间不足,或针对更常见的 64 位操作系统,则是根据 arenaHint 尝试在对应的地址进行扩容:
func (h *mheap) sysAlloc(n uintptr, hintList **arenaHint, register bool) (v unsafe.Pointer, size uintptr) {
...
for *hintList != nil {
hint := *hintList
p := hint.addr
// 支持从高地址向低地址扩展
// 主要是为了支持栈空间扩展
if hint.down {
p -= n
}
_// 地址合法性检查_
if p+n < p {
// _扩展后地址溢出,不合法_
v = nil
} else if arenaIndex(p+n-1) >= 1<<arenaBits {
// 地址超出了堆内存空间可寻址范围,不合法
v = nil
} else {
// 尝试将对应地址区域设置为 sysReserved 状态
v = sysReserve(unsafe.Pointer(p), n)
}
if p == uintptr(v) {
_// 成功分配到对应位置_
if !hint.down {
p += n
}
hint.addr = p // _更新 hint 相关信息_
size = n // 设置返回大小
break // 分配成功,跳出循环
}
// 分配失败:_释放临时地址并移除该 hint_
if v != nil {
sysFreeOS(v, n)
}
*hintList = hint.next
h.arenaHintAlloc.free(unsafe.Pointer(hint))
// 继续循环,尝试下一个 hint(如有)
}
...
}
如果上述分配策略都失败,则采取下列回退机制,尝试任意地址分配,可用地址由操作系统内核指定。需要注意的是,不同环境下的分配策略可能有出入:
func (h *mheap) sysAlloc(n uintptr, hintList **arenaHint, register bool) (v unsafe.Pointer, size uintptr) {
...
if size == 0 {
...
_// 委托系统内核选择任意可用地址_
v, size = sysReserveAligned(nil, n, heapArenaBytes)
if v == nil {
return nil, 0
}
// 创建新的双向扩展 arenaHint
hint := (*arenaHint)(h.arenaHintAlloc.alloc())
hint.addr, hint.down = uintptr(v), true
hint.next, mheap_.arenaHints = mheap_.arenaHints, hint
hint = (*arenaHint)(h.arenaHintAlloc.alloc())
hint.addr = uintptr(v) + size
hint.next, mheap_.arenaHints = mheap_.arenaHints, hint
}
...
}
再次检查分配的内存区域是否可用,严格检查边界是否合法:
func (h *mheap) sysAlloc(n uintptr, hintList **arenaHint, register bool) (v unsafe.Pointer, size uintptr) {
...
// 检查地址是否合法
{
var bad string
p := uintptr(v)
if p+size < p {
// _扩展后地址溢出,不合法_
bad = "region exceeds uintptr range"
} else if arenaIndex(p) >= 1<<arenaBits {
// 起始地址超出了堆内存空间可寻址范围,不合法
bad = "base outside usable address space"
} else if arenaIndex(p+size-1) >= 1<<arenaBits {
// 结束地址超出了堆内存空间可寻址范围,不合法
bad = "end outside usable address space"
}
if bad != "" {
// 不合法地址抛出异常
print("runtime: memory allocated by OS [", hex(p), ", ", hex(p+size), ") not in usable address space: ", bad, "\n")
throw("memory reservation exceeds address space limit")
}
}
_// 检查对齐情况(必须和 heapArenaBytes 对齐)_
if uintptr(v)&(heapArenaBytes-1) != 0 {
throw("misrounded allocation in sysAlloc")
}
...
}
分配好内存空间后,将创建一个 heapArena 用于管理新分配的内存空间:
func (h *mheap) sysAlloc(n uintptr, hintList **arenaHint, register bool) (v unsafe.Pointer, size uintptr) {
...
mapped:
// 遍历内存范围内所有需要的 Arena 索引
for ri := arenaIndex(uintptr(v)); ri <= arenaIndex(uintptr(v)+size-1); ri++ {
l2 := h.arenas[ri.l1()]
if l2 == nil {
// 实现**延迟分配策略**:只有在需要时才分配L2索引块
l2 = (*[1 << arenaL2Bits]*heapArena)(sysAllocOS(unsafe.Sizeof(*l2)))
if l2 == nil {
throw("out of memory allocating heap arena map")
}
// 参考 src/runtime/mem_{OS}.go
// 根据系统配置选择是否使用大页优化,提升内存访问性能。
// 目前主要针对 Linux 环境,参考 src/runtime/mem_linux.go
if h.arenasHugePages {
sysHugePage(unsafe.Pointer(l2), unsafe.Sizeof(*l2))
} else {
sysNoHugePage(unsafe.Pointer(l2), unsafe.Sizeof(*l2))
}
// 使用原子操作确保并发安全
atomic.StorepNoWB(unsafe.Pointer(&h.arenas[ri.l1()]), unsafe.Pointer(l2))
}
if l2[ri.l2()] != nil {
throw("arena already initialized")
}
var r *heapArena
// 从专用分配器heapArenaAlloc分配(性能更好)
r = (*heapArena)(h.heapArenaAlloc.alloc(unsafe.Sizeof(*r), goarch.PtrSize, &memstats.gcMiscSys))
if r == nil {
// 备选:使用persistentalloc分配(永久分配)
r = (*heapArena)(persistentalloc(unsafe.Sizeof(*r), goarch.PtrSize, &memstats.gcMiscSys))
if r == nil {
throw("out of memory allocating heap arena metadata")
}
}
_// 注册到全局 arena 列表_
if register {
_// 动态扩展 allArenas 切片_
if len(h.allArenas) == cap(h.allArenas) {
_// 容量翻倍策略_
size := 2 * uintptr(cap(h.allArenas)) * goarch.PtrSize
if size == 0 {
size = physPageSize
}
// 分配新切片并进行迁移旧切片中的 heapArena
newArray := (*notInHeap)(persistentalloc(size, goarch.PtrSize, &memstats.gcMiscSys))
if newArray == nil {
throw("out of memory allocating allArenas")
}
oldSlice := h.allArenas
*(*notInHeapSlice)(unsafe.Pointer(&h.allArenas)) = notInHeapSlice{newArray, len(h.allArenas), int(size / goarch.PtrSize)}
copy(h.allArenas, oldSlice)
// 旧数组不释放:避免并发读风险
}
h.allArenas = h.allArenas[:len(h.allArenas)+1]
h.allArenas[len(h.allArenas)-1] = ri
}
_// 原子存储 heapArena 指针_
atomic.StorepNoWB(unsafe.Pointer(&l2[ri.l2()]), unsafe.Pointer(r))
}
...
}
代码中有针对大页进行优化,主要是在 Linux 环境下给内核建议针对给定内存区域是否启用大页优化。会根据根据内存用途选择是否启用大页,目的是减少 TLB(Translation Lookaside Buffer)缺失,提升内存访问性能。
- 普通页访问:内存访问 → TLB 查找 → 页表遍历(多级) → 物理地址
- 大页访问:内存访问 → TLB 查找 → 物理地址(减少页表层级)
// src/runtime/malloc.go
var (
physHugePageSize uintptr
physHugePageShift uint
)
physHugePageSize:- 表示操作系统默认的物理大页尺寸(以字节为单位)
- 由操作系统初始化代码设置(通常在
osinit函数中) - 必须保证是 2 的幂次(运行时验证)
physHugePageShift:- 定义关系:
physHugePageSize = 1 << physHugePageShift - 用于将除法操作转换为位移操作,优化性能
- 示例:当大页为 2MB(1<<21)时,
physHugePageShift=21
- 定义关系:
// src/runtime/mem_linux.go
func sysHugePageOS(v unsafe.Pointer, n uintptr) {
if physHugePageSize != 0 {
_// 向上对齐到大页边界_
beg := alignUp(uintptr(v), physHugePageSize)
_// 向下对齐到大页边界_
end := alignDown(uintptr(v)+n, physHugePageSize)
if beg < end {
// 告诉内核这块内存区域适合用大页支持
madvise(unsafe.Pointer(beg), end-beg, _MADV_HUGEPAGE)
}
}
}
func sysNoHugePageOS(v unsafe.Pointer, n uintptr) {
// 确保地址按普通页大小对齐
if uintptr(v)&(physPageSize-1) != 0 {
// The Linux implementation requires that the address
// addr be page-aligned, and allows length to be zero.
throw("unaligned sysNoHugePageOS")
}
// 告诉内核这块内存区域不适合用大页
madvise(v, n, _MADV_NOHUGEPAGE)
}
虚拟内存管理
虚拟内存管理主要通过系统调用直接操作虚拟内存,切换内存区域状态,不同操作系统环境下的实现可能有所不同,以下主要以 Linux 操作系统为例进行细致解析:
// sysAllocOS 分配未经初始化的物理内存
//go:nosplit
func sysAllocOS(n uintptr) unsafe.Pointer {
// 使用mmap创建匿名私有映射(MAP_ANON|MAP_PRIVATE)
// 设置读写权限(PROT_READ|PROT_WRITE)
p, err := mmap(nil, n, _PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_PRIVATE, -1, 0)
if err != 0 {
if err == _EACCES {
print("runtime: mmap: access denied\n")
exit(2)
}
if err == _EAGAIN {
print("runtime: mmap: too much locked memory (check 'ulimit -l').\n")
exit(2)
}
return nil
}
return p
}
var adviseUnused = uint32(_MADV_FREE)
const madviseUnsupported = 0
// sysUnusedOS 释放物理内存但保留虚拟地址空间
// 标记内存区域为未使用状态,告知操作系统可以回收
func sysUnusedOS(v unsafe.Pointer, n uintptr) {
if uintptr(v)&(physPageSize-1) != 0 || n&(physPageSize-1) != 0 {
// 内存没有对齐,可能导致意外释放正在使用的内存
throw("unaligned sysUnused")
}
advise := atomic.Load(&adviseUnused)
if debug.madvdontneed != 0 && advise != madviseUnsupported {
advise = _MADV_DONTNEED
}
switch advise {
case _MADV_FREE:
// **首选** MADV_FREE(Linux 4.5+): 内核可回收页面,但保留内容(性能最优)
if madvise(v, n, _MADV_FREE) == 0 {
break
}
atomic.Store(&adviseUnused, _MADV_DONTNEED)
fallthrough
case _MADV_DONTNEED:
// **备选** MADV_DONTNEED: 立即释放物理页(访问时重新分配)
if madvise(v, n, _MADV_DONTNEED) == 0 {
break
}
atomic.Store(&adviseUnused, madviseUnsupported)
fallthrough
case madviseUnsupported:
// 由于 3.18+ madvise 支持可选
// **回退** mmap重映射:兼容旧内核
mmap(v, n, _PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_FIXED|_MAP_PRIVATE, -1, 0)
}
// 启用 debug.harddecommit 时完全移除内存权限
if debug.harddecommit > 0 {
p, err := mmap(v, n, _PROT_NONE, _MAP_ANON|_MAP_FIXED|_MAP_PRIVATE, -1, 0)
if p != v || err != 0 {
throw("runtime: cannot disable permissions in address space")
}
}
}
// sysUsedOS 重新启用之前标记为未使用的内存
func sysUsedOS(v unsafe.Pointer, n uintptr) {
// 仅启用 debug.harddecommit 时才进行显式操作
if debug.harddecommit > 0 {
p, err := mmap(v, n, _PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_FIXED|_MAP_PRIVATE, -1, 0)
if err == _ENOMEM {
throw("runtime: out of memory")
}
if p != v || err != 0 {
throw("runtime: cannot remap pages in address space")
}
return
}
}
// sysFreeOS 完全释放内存
//go:nosplit
func sysFreeOS(v unsafe.Pointer, n uintptr) {
// 直接调用munmap系统调用,同时释放虚拟和物理内存资源
munmap(v, n)
}
// sysFaultOS 内存隔离
// 将内存设为不可访问状态
func sysFaultOS(v unsafe.Pointer, n uintptr) {
mprotect(v, n, _PROT_NONE) // 禁止读写/执行
madvise(v, n, _MADV_DONTNEED) // 释放物理页
}
// sysReserveOS 预留地址空间
// 预留虚拟地址空间但不分配物理内存,零开销保留大块连续地址空间
func sysReserveOS(v unsafe.Pointer, n uintptr) unsafe.Pointer {
p, err := mmap(v, n, _PROT_NONE, _MAP_ANON|_MAP_PRIVATE, -1, 0)
if err != 0 {
return nil
}
return p
}
// sysMapOS 提交预留地址
// 在预留的地址空间上映射可用内存
func sysMapOS(v unsafe.Pointer, n uintptr) {
// mmap 带MAP_FIXED重映射为读写内存
p, err := mmap(v, n, _PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_FIXED|_MAP_PRIVATE, -1, 0)
if err == _ENOMEM {
throw("runtime: out of memory")
}
if p != v || err != 0 {
print("runtime: mmap(", v, ", ", n, ") returned ", p, ", ", err, "\n")
throw("runtime: cannot map pages in arena address space")
}
...
}
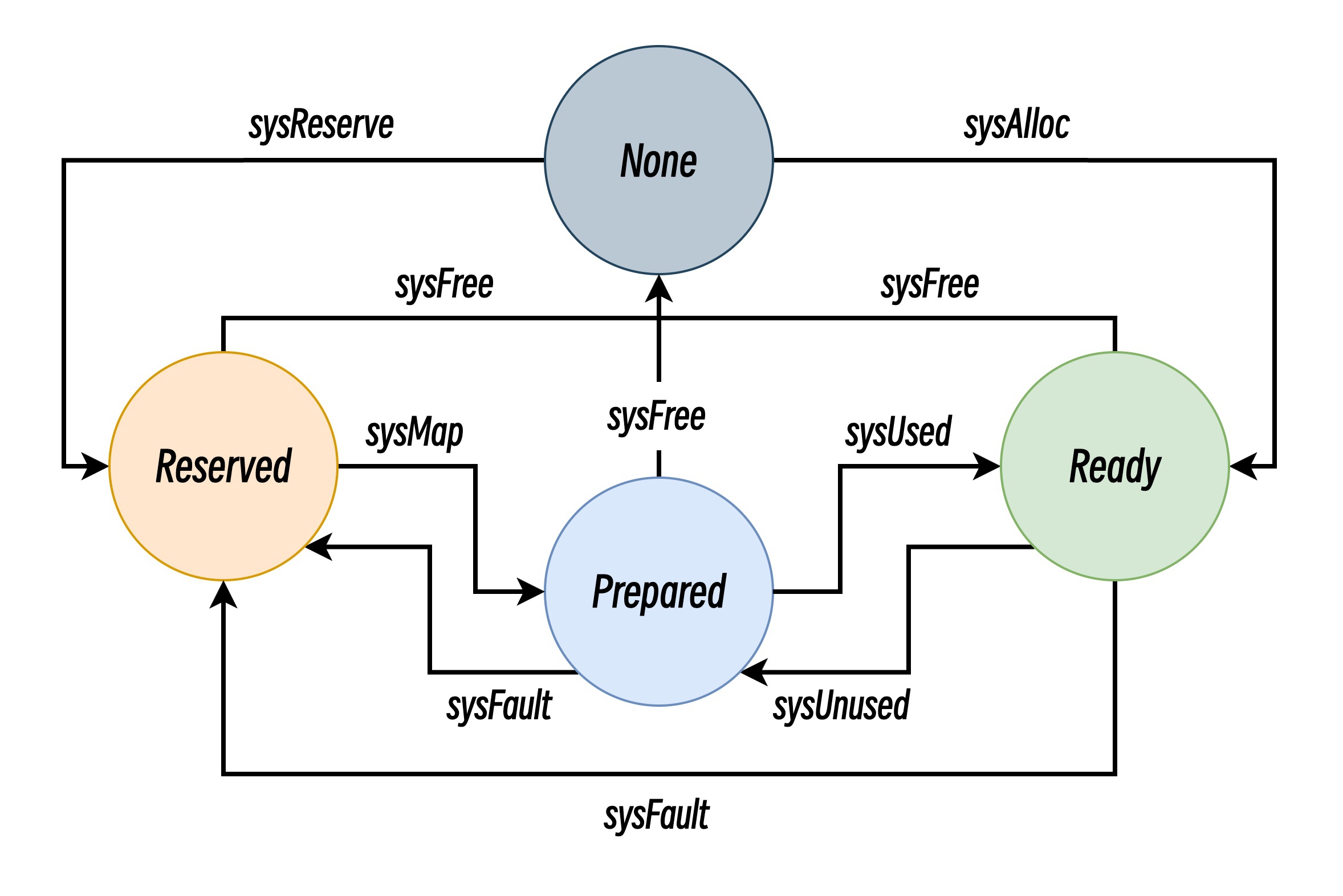
对象管理
前面的内容详细的描述了 Go 是如何通过各个组件进行内存管理,而归根结底就是为了管理程序中堆对象的内存分配和回收。 下面,我们先看看 Go 是创建一个对象并为其分配堆内存的。
func newobject(typ *_type) unsafe.Pointer {
return mallocgc(typ.Size_, typ, true)
}
大部分的堆对象都由 runtime.newobject 创建并分配内存,从传入的 _type 元数据中获取该类型实例所需的确切内存大小,并调用 mallocgc 来实际分配内存。
//go:linkname mallocgc
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
// Actually do the allocation.
var x unsafe.Pointer
var elemsize uintptr
if size <= maxSmallSize-mallocHeaderSize {
if typ == nil || !typ.Pointers() {
if size < maxTinySize {
x, elemsize = mallocgcTiny(size, typ, needzero)
} else {
x, elemsize = mallocgcSmallNoscan(size, typ, needzero)
}
} else if heapBitsInSpan(size) {
x, elemsize = mallocgcSmallScanNoHeader(size, typ, needzero)
} else {
x, elemsize = mallocgcSmallScanHeader(size, typ, needzero)
}
} else {
x, elemsize = mallocgcLarge(size, typ, needzero)
}
...
return x
}
从代码可以看出,Go 针对不同大小的对象提供了不同的内存分配策略,也就是先前说的对象大小分级管理策略。
微对象
mallocgcTiny 的核心目标是优化小于 16 字节(maxTinySize) 的 noscan(无指针)对象的分配效率,通过合并多个微小对象到一个内存块中,减少内存碎片和分配开销。
func mallocgcTiny(size uintptr, typ *_type, needzero bool) (unsafe.Pointer, uintptr) {
// Set mp.mallocing to keep from being preempted by GC.
mp := acquirem()
// 启用二次安全检查
if doubleCheckMalloc {
// 防止分配死锁
if mp.mallocing != 0 {
throw("malloc deadlock")
}
// 防止在信号处理 Goroutine 中进行分配
if mp.gsignal == getg() {
throw("malloc during signal")
}
// 确保对象为 noscan, 不支持分配指针
if typ != nil && typ.Pointers() {
throw("expected noscan for tiny alloc")
}
}
// 修改标志位标识正在进行分配
mp.mallocing = 1
// 从 Per-P mcache 获取当前 Tiny 块中已分配的偏移量
c := getMCache(mp)
off := c.tinyoffset
// 根据对象大小 size 调整偏移量 off 以满足对齐要求
if size&7 == 0 {
off = alignUp(off, 8) _// 8 字节对齐_
} else if goarch.PtrSize == 4 && size == 12 {
_// 在 32 位系统上,某些 12 字节的结构体可能包含 64 位字段,_
// _如果这些字段没有正确对齐,会导致原子操作失败或程序崩溃。_
off = alignUp(off, 8)
} else if size&3 == 0 {
_// 4 字节对齐_
off = alignUp(off, 4)
} else if size&1 == 0 {
_// 2 字节对齐_
off = alignUp(off, 2)
}
// 当前内存块还有剩余空间,尝试从当前 Tiny Block 分配
if off+size <= maxTinySize && c.tiny != 0 {
x := unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.tinyAllocs++
mp.mallocing = 0
releasem(mp)
return x, 0
}
// 空间不足,分配新的 Tiny Block
checkGCTrigger := false
span := c.alloc[tinySpanClass] // 从缓存获取新块
// 通过位运算和加法统计低位连续0的位数
// 快速获取对应大小的内存区域
v := nextFreeFast(span)
if v == 0 {
// 处理 span 空间耗尽的情况
// 会进行 mcache.refill 重新获取可用 span
// 再给对象分配可用空间
v, span, checkGCTrigger = c.nextFree(tinySpanClass)
}
x := unsafe.Pointer(v)
// 初始化内存为 0, 强行转换成 [2]uint64, 清空 16 字节内存
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
if !raceenabled && (size < c.tinyoffset || c.tiny == 0) {
// 替换旧内存区域
c.tiny = uintptr(x)
c.tinyoffset = size
}
// publicationBarrier 确保在**弱内存序架构**(如 ARM、PowerPC)上,内存写入操作按照正确的顺序对其他处理器核心可见。
// 避免乱序内存操作可见性导致的 GC 可能读取到随机数据,错误识别指针,跟踪无效指针等问题
publicationBarrier()
// 设置 span.freeIndexForScan,防止 GC 错误扫描未分配区域。
span.freeIndexForScan = span.freeindex
// 插入写屏障生效中,证明处于 GC 标记阶段,
// 直接将新分配的对象标黑
if writeBarrier.enabled {
gcmarknewobject(span, uintptr(x))
}
...
// 重置分配标志
mp.mallocing = 0
releasem(mp)
// 检查是否需要触发 GC
if checkGCTrigger {
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(t)
}
}
...
return x, span.elemsize
}
小对象
针对小对象的分配情况就比较复杂,涉及以下三个函数,针对对象的内存分配逻辑整体区别不大,下面仅给出关键部分逻辑和区别:
func mallocgcSmallNoscan(size uintptr, typ *_type, needzero bool) (unsafe.Pointer, uintptr) {
mp := acquirem()
...
mp.mallocing = 1
...
c := getMCache(mp)
var sizeclass uint8
// 使用预定义的大小类别来减少内存碎片
if size <= _smallSizeMax_-8 {
// **小尺寸段 (≤ smallSizeMax-8)**
// smallSizeMax 通常是 1024 字节,smallSizeDiv 通常是 8
// 使用 8 字节粒度的查找表
sizeclass = size_to_class8[divRoundUp(size, _smallSizeDiv_)]
} else {
// **大尺寸段 (> smallSizeMax-8)**
// largeSizeDiv 通常是 128
// 使用 128 字节粒度的查找表
sizeclass = size_to_class128[divRoundUp(size-_smallSizeMax_, _largeSizeDiv_)]
}
size = uintptr(class_to_size[sizeclass])
// 获取对应的 noscan spanclass
spc := makeSpanClass(sizeclass, true)
span := c.alloc[spc]
// 通过位运算和加法统计低位连续0的位数
// 快速获取对应大小的内存区域
v := nextFreeFast(span)
if v == 0 {
// 处理 span 空间耗尽的情况
// 会进行 mcache.refill 重新获取可用 span
// 再给对象分配可用空间
v, span, checkGCTrigger = c.nextFree(spc)
}
x := unsafe.Pointer(v)
// 需要清空内存的情况
if needzero && span.needzero != 0 {
memclrNoHeapPointers(x, size)
}
publicationBarrier()
span.freeIndexForScan = span.freeindex
if writeBarrier.enabled {
gcmarknewobject(span, uintptr(x))
}
...
mp.mallocing = 0
releasem(mp)
...
return x, size
}
func mallocgcSmallScanNoHeader(size uintptr, typ *_type, needzero bool) (unsafe.Pointer, uintptr) {
mp := acquirem()
...
mp.mallocing = 1
...
c := getMCache(mp)
sizeclass := size_to_class8[divRoundUp(size, _smallSizeDiv_)]
spc := makeSpanClass(sizeclass, false)
span := c.alloc[spc]
v := nextFreeFast(span)
if v == 0 {
v, span, checkGCTrigger = c.nextFree(spc)
}
x := unsafe.Pointer(v)
if needzero && span.needzero != 0 {
memclrNoHeapPointers(x, size)
}
if goarch._PtrSize _== 8 && sizeclass == 1 {
// initHeapBits already set the pointer bits for the 8-byte sizeclass
// on 64-bit platforms.
c.scanAlloc += 8
} else {
c.scanAlloc += heapSetTypeNoHeader(uintptr(x), size, typ, span)
}
size = uintptr(class_to_size[sizeclass])
publicationBarrier()
span.freeIndexForScan = span.freeindex
if writeBarrier.enabled {
gcmarknewobject(span, uintptr(x))
}
...
mp.mallocing = 0
releasem(mp)
...
return x, size
}
func mallocgcSmallScanHeader(size uintptr, typ *_type, needzero bool) (unsafe.Pointer, uintptr) {
mp := acquirem()
...
mp.mallocing = 1
...
c := getMCache(mp)
var sizeclass uint8
// 使用预定义的大小类别来减少内存碎片
if size <= _smallSizeMax_-8 {
// **小尺寸段 (≤ smallSizeMax-8)**
// smallSizeMax 通常是 1024 字节,smallSizeDiv 通常是 8
// 使用 8 字节粒度的查找表
sizeclass = size_to_class8[divRoundUp(size, _smallSizeDiv_)]
} else {
// **大尺寸段 (> smallSizeMax-8)**
// largeSizeDiv 通常是 128
// 使用 128 字节粒度的查找表
sizeclass = size_to_class128[divRoundUp(size-_smallSizeMax_, _largeSizeDiv_)]
}
size = uintptr(class_to_size[sizeclass])
// 获取对应的 noscan spanclass
spc := makeSpanClass(sizeclass, true)
span := c.alloc[spc]
// 通过位运算和加法统计低位连续0的位数
// 快速获取对应大小的内存区域
v := nextFreeFast(span)
if v == 0 {
// 处理 span 空间耗尽的情况
// 会进行 mcache.refill 重新获取可用 span
// 再给对象分配可用空间
v, span, checkGCTrigger = c.nextFree(spc)
}
x := unsafe.Pointer(v)
// 需要清空内存的情况
if needzero && span.needzero != 0 {
memclrNoHeapPointers(x, size)
}
header := (**_type)(x)
x = add(x, _mallocHeaderSize_)
c.scanAlloc += heapSetTypeSmallHeader(uintptr(x), size-_mallocHeaderSize_, typ, header, span)
publicationBarrier()
span.freeIndexForScan = span.freeindex
if writeBarrier.enabled {
gcmarknewobject(span, uintptr(x))
}
...
mp.mallocing = 0
releasem(mp)
...
return x, size
}
mallocgc 函数通过下列函数判断是否可以进行指针位图内嵌
// minSizeForMallocHeader 确保对象的指针位图能被**单个 uintptr 存储**
_minSizeForMallocHeader _= goarch._PtrSize _* _ptrBits_
func heapBitsInSpan(userSize uintptr) bool {
// 正常来说 64-bit 操作系统
// _minSizeForMallocHeader 典型值为 512 字节_
return userSize <= _minSizeForMallocHeader_
}
mallocgcSmallNoscan- 对象类型:
noscan对象,不包含任何指针(通过typ.Pointers()验证),对应 spanclass 由makeSpanClass(sizeclass, true)的noscan=true参数控制 - 额外开销:无额外开销,仅分配对象内存;
- 指针处理:无指针扫描开销,省略指针位图分配和操作。
- GC 策略:只需
gcmarknewobject黑色标记。
- 对象类型:
mallocgcSmallScanNoHeader- 对象类型:
scan对象,包含指针类型 - 额外开销:分配对象内存,还需要额外的指针位图;
- 指针处理:指针位图内嵌,指针元数据存储在 Span 的 heapBits 区域
- GC 策略:需要对指针内嵌位图进行扫描
- 对象类型:
mallocgcSmallScanHeader- 对象类型:
scan对象,包含指针类型; - 额外开销:分配对象内存,还_需要额外头部存储类型信息;_
- 指针处理:需要额外头部存放指针位图;
- GC 策略:需要对额外头部进行扫描;
- 对象类型:
大对象
func mallocgcLarge(size uintptr, typ *_type, needzero bool) (unsafe.Pointer, uintptr) {
mp := acquirem()
...
mp.mallocing = 1
...
c := getMCache(mp)
// 直接调用 mcache.allocLarge 进行大 Span 分配
span := c.allocLarge(size, typ == nil || !typ.Pointers())
// 设置 span 元数据
span.freeindex = 1
span.allocCount = 1
span.largeType = nil // 要求 GC 先忽略该对象
size = span.elemsize
x := unsafe.Pointer(span.base())
publicationBarrier()
span.freeIndexForScan = span.freeindex
if writeBarrier.enabled {
gcmarknewobject(span, uintptr(x))
}
...
mp.mallocing = 0
releasem(mp)
...
// 稍微有点不同的是,分配大对象会强制检查是否需要触发 GC
if t := (gcTrigger{kind: _gcTriggerHeap_}); t.test() {
gcStart(t)
}
// 当对象**包含指针,或 span 需要清零操作**
if noscan := typ == nil || !typ.Pointers(); !noscan || (needzero && span.needzero != 0) {
// N.B. size == fullSize always in this case.
// 这个清零操作是潜在调度**抢占点**:运行时间长的清零操作可能被调度器中断
memclrNoHeapPointersChunked(size, x)
mp := acquirem()
// 为包含指针的对象设置GC扫描所需的类型元数据
if !noscan {
getMCache(mp).scanAlloc += heapSetTypeLarge(uintptr(x), size, typ, span)
}
// 确保类型信息对其他线程可见
publicationBarrier()
releasem(mp)
}
return x, size
}
小结
Go 的内存分配器在很大程度上借鉴了 Google 的 TCMalloc (Thread-Caching Malloc)。其核心思想是分级管理和空间换时间,通过为每个处理器(P)设置本地缓存来减少锁竞争,从而实现高效的并发内存分配。
以下是理解 Go 内存管理所必须知道的几个关键数据结构:
mspan(Memory Span)- 定义:内存管理的基本单位。它是一个包含整数个(1 到 N)连续物理页(Page,在 Go 中通常是 8KB)的内存块。
- 作用:一个
mspan会被格式化,用于存储特定大小等级(Size Class)的对象。例如,一个mspan可能专门用来存放 16 字节的对象,另一个则专门存放 32 字节的对象。 - 状态:
mspan有多种状态,如mSpanInUse(已分配给 mcache/mcentral)、mSpanManual(用于大对象分配)、mSpanFree(在 mheap 的空闲列表中)等。
mcache(Memory Cache)- 定义:每个处理器
P(GOMAXPROCS决定了 P 的数量)独有的线程本地缓存。它是一个包含所有 Size Class 的mspan列表的数组。 - 作用:这是内存分配的快速通道。当一个 Goroutine 需要分配一个小对象时,它会直接从其绑定的
P的mcache中获取。因为mcache是 P 私有的,所以分配过程完全无锁,速度极快。
- 定义:每个处理器
mcentral(Central Cache)- 定义:一个全局中心缓存,按 Size Class 组织。每个 Size Class 对应一个
mcentral实例。 - 作用:当一个
mcache中某个 Size Class 的mspan被用完时,它会向对应的mcentral"申请" 一个新的mspan。反之,如果mcache中有多余的mspan,也会归还给mcentral。mcentral是所有P共享的,所以访问mcentral需要加锁。
- 定义:一个全局中心缓存,按 Size Class 组织。每个 Size Class 对应一个
mheap(Heap Arena)- 定义:全局堆,是内存的最终来源。它管理着从操作系统申请来的大块内存(称为 Arena,在 64 位系统上是 64MB)。
- 作用:
- 当
mcentral中没有空闲的mspan时,它会向mheap申请。 mheap会从其管理的 Arena 中切分出一个合适的mspan给mcentral。- 如果
mheap自身也没有足够的内存,它会向操作系统申请新的 Arena。 mheap还负责管理那些未被使用的mspan(空闲列表),并触发垃圾回收。
- 当
层级关系总结: mheap → mcentral → mcache → Goroutine
mheap从 OS 批发内存。mcentral从mheap按需领取mspan。mcache从mcentral按需领取mspan。- Goroutine 从
mcache中快速、无锁地分配对象。
当代码中出现 new(T)、make([]T, n) 或其他导致堆分配的操作时,Go 运行时会调用 mallocgc 函数。其流程根据对象大小分为三类:
- 微小对象分配 (< 16B)
- 这类极小的对象会通过
mcache中的一个特殊分配器进行合并分配,以提高内存利用率和减少分配次数。
- 这类极小的对象会通过
- 小对象分配 (16B <= size <= 32KB)
- 这是最常见的路径,也是 Go 高效分配的核心。
- Step 1 (Fast Path):计算对象所需的 Size Class,尝试从当前 Goroutine 绑定的
P的mcache中获取。由于无锁,这个过程非常快。 - Step 2 (Slow Path):如果
mcache中对应的mspan已满,mcache会向mcentral申请一个新的、可用的mspan。此过程需要加锁。 - Step 3 (Slower Path):如果
mcentral中也没有可用的mspan,mcentral会向mheap申请。mheap会从其空闲mspan列表中查找,或者从 Arena 中切分一个新的。 - Step 4 (Final Path):如果
mheap也没有足够的内存,它会向操作系统申请一个新的 Arena(例如 64MB)。
- 大对象分配 (> 32KB)
- 大对象不会经过
mcache和mcentral。 - 它们会直接从
mheap中进行分配。mheap会找到能容纳该对象的最小整数页(8KB 的倍数)的mspan。 - 这种设计是合理的,因为大对象分配不频繁,为其在
mcache中缓存意义不大,反而会浪费缓存空间。
- 大对象不会经过
