Go 栈内存管理浅析
寄存器
寄存器是中央处理器(CPU)中的稀缺资源,它的存储能力非常有限,但是能提供最快的读写速度,充分利用寄存器的速度可以构建高性能的应用程序。寄存器在物理机上非常有限,然而栈区的操作会使用到两个以上的寄存器,这足以说明栈内存在应用程序的重要性。
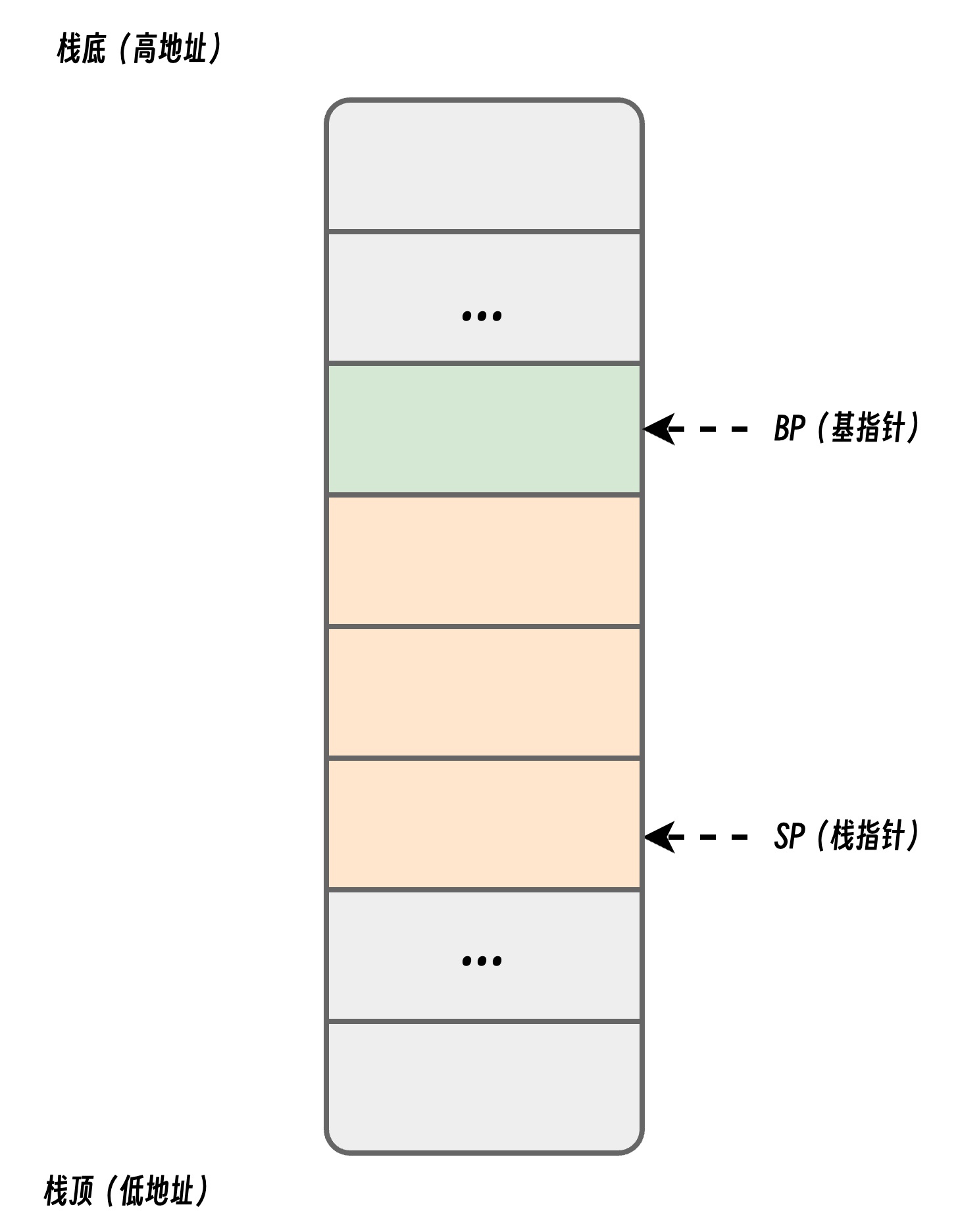
栈寄存器是 CPU 寄存器中的一种,它的主要作用是跟踪函数的调用栈,Go 语言的汇编代码包含 BP 和 SP 两个栈寄存器,它们分别存储了栈的基址指针和栈顶的地址,栈内存与函数调用的关系非常紧密,我们在函数调用一节中曾经介绍过栈区,BP 和 SP 之间的内存就是当前函数的调用栈。
因为历史原因,栈区内存都是从高地址向低地址扩展的,当应用程序申请或者释放栈内存时只需要修改 SP 寄存器的值,这种线性的内存分配方式与堆内存相比更加快速,仅会带来极少的额外开销。
线程栈和协程栈
大多数应用程序常用线程模型,如果我们在 Linux 操作系统中执行 pthread_create 系统调用,进程会启动一个新的线程,一般来说默认栈大小是 8MB (Windows 1MB)。进程、线程、协程在程序执行的过程中扮演者不同的角色,一般来说,调度和切换开销依次递减。Go 为了实现高并发,在设计时就采用了协程模型,在用户态实现了协程的上下文(协程栈)管理和切换。
| 特性 | 进程 (Process) | 线程 (Thread) | 协程 (Goroutine) |
|---|---|---|---|
| 定义 | 操作系统资源分配的基本单位 | CPU调度的基本单位 | 用户态轻量级线程(协作式任务) |
| 资源隔离 | 独立内存空间、文件句柄等 | 共享进程内存空间 | 共享线程内存空间 |
| 切换开销 | 高(涉及CPU上下文+资源切换) | 中(仅CPU上下文切换) | 极低(用户态自主切换) |
| 调度方式 | 操作系统内核调度 | 操作系统内核调度 | 用户程序自主调度 |
| 并发能力 | 多进程并行 | 多线程并行/并发 | 单线程内高并发(Go 通过设计高效的调度器实现多线程绑定执行) |
| 典型应用 | 独立程序 | 多任务处理 | 高并发IO密集型任务 |
函数调用规约
下列这幅图所展示的就是一个 栈帧 的结构。也可以说栈桢是栈给一个函数分配的栈空间,它包括了函数调用者地址、本地变量、返回值地址、调用者参数等信息。其中 caller 是调用方,callee 是被调用方。
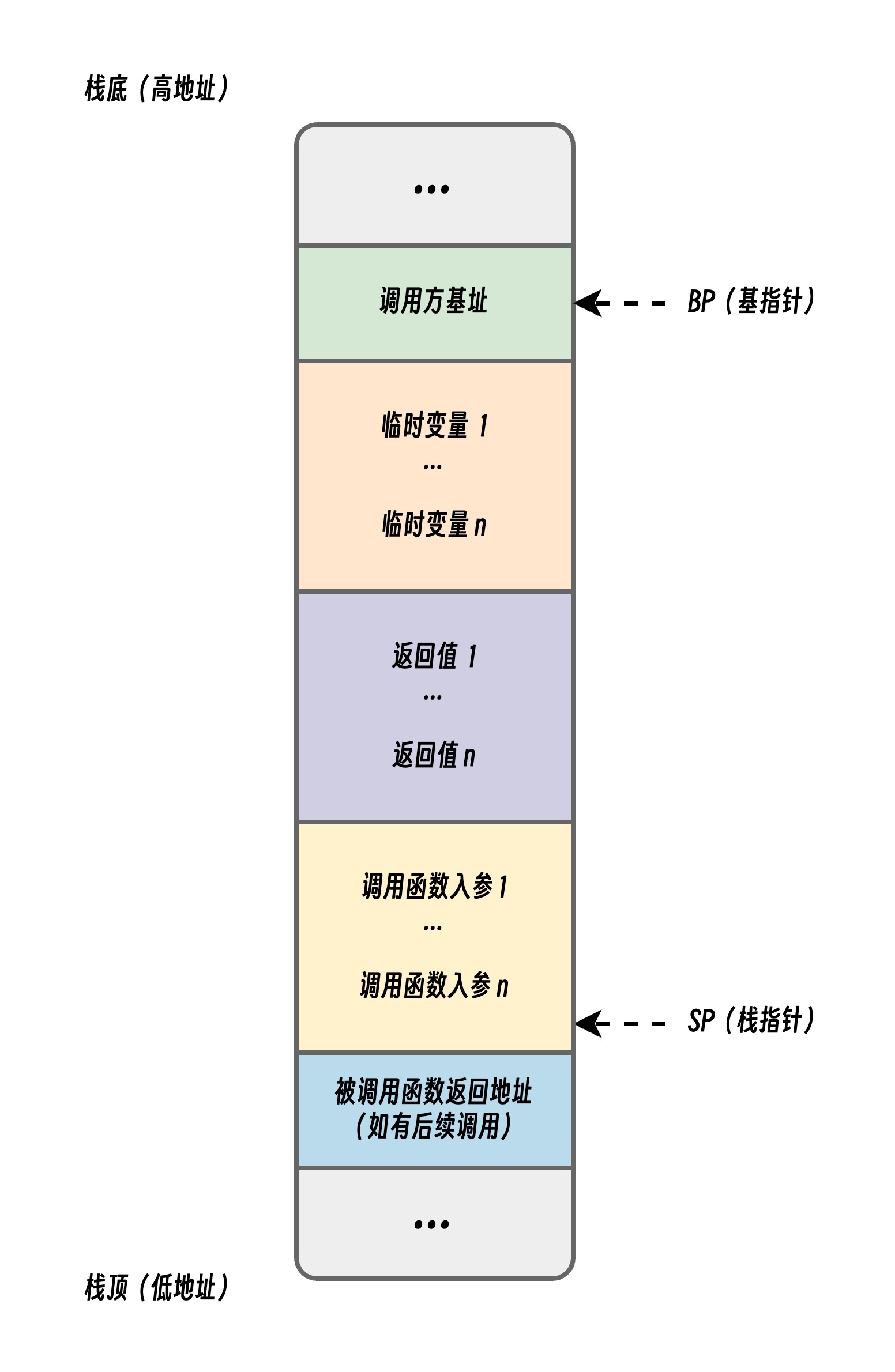
这里有几个注意点,图中的 BP、SP 都表示对应的寄存器。
- BP:基址指针寄存器(extended base pointer),也叫帧指针,存放着一个指针,表示函数栈开始的地方。
- SP:栈指针寄存器(extended stack pointer),存放着一个指针,存储的是函数栈空间的栈顶,也就是函数栈空间分配结束的地方,注意这里是硬件寄存器,不是 Plan9 中的伪寄存器。
BP与SP放在一起,一个表示开始(栈顶)、一个表示结束(栈低)。
逃逸分析
在 C / C++ 这类需要手动管理内存的编程语言中,将对象或结构体分配到栈内存还是堆内存上是由开发者决定的。但是手动分配内存可能导致某些特定的问题:
- 不需要分配到堆上的对象分配到了堆上 ,不仅浪费内存空间,还增加分配和访问延迟;
#include <stdio.h>
#include <stdlib.h>
int add_one(int origin) {
int *p = malloc(sizeof(int)); // 简单类型分配到堆上,导致浪费
int pp;
*p = 1;
pp = origin + *p;
// free(p); 忘记释放导致内存泄露
return pp;
}
- 需要分配到堆上的变量分配到了栈上,保存在栈上的变量被释放后,可能导致指针悬挂,影响内存安全,导致程序崩溃或引发安全问题。
// 下列函数返回栈上变量指针,函数结束后变量会被销毁,导致指针悬挂
int* dangling_pointer() {
int p = 1;
return &p;
}
在编译器优化中,逃逸分析是用来决定指针作用域的方法。Go 语言的编译器使用逃逸分析决定哪些变量应该在栈上分配,哪些变量应该在堆上分配,其中包括使用 new、make 和字面量等方法隐式分配的内存,Go 语言的逃逸分析遵循以下两个不变性:
- 指向栈对象的指针不能存在于堆中;
- 指向栈对象的指针不能在栈对象回收后存活;
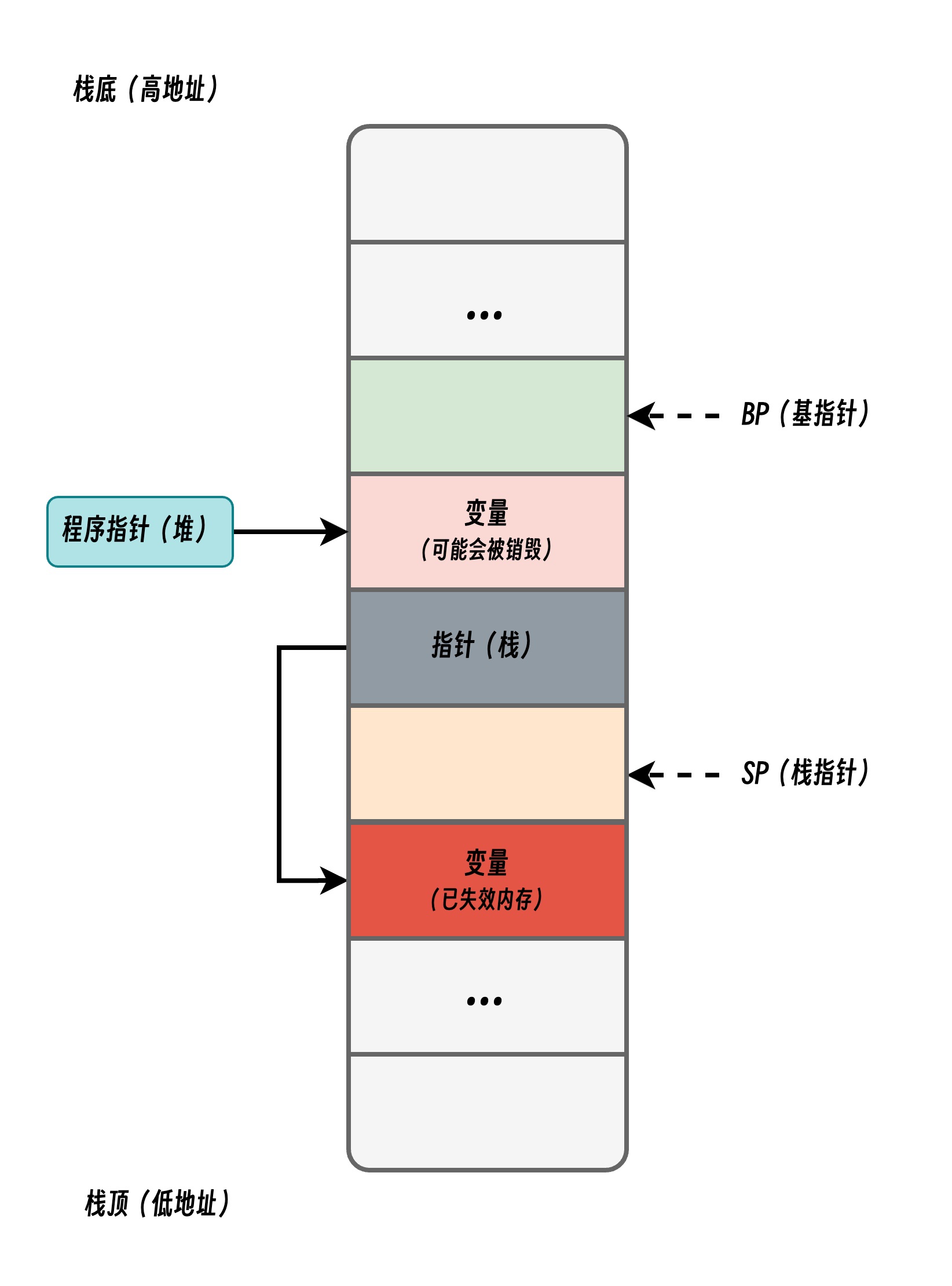
我们通过上图展示两条不变性存在的意义,当我们违反了第一条不变性时,堆上的指针指向了栈中的变量,一旦函数返回后函数栈会被回收,该绿色指针指向的值就不再合法;如果我们违反了第二条不变性,因为寄存器 SP 下面的内存由于函数返回已经释放,所以栈指针指向的内存已经不再合法。
逃逸分析是静态分析的一种,在编译器解析了 Go 语言源文件后,它可以获得整个程序的抽象语法树(Abstract syntax tree,AST),编译器可以根据抽象语法树分析静态的数据流,我们会通过以下几个步骤实现静态分析的全过程。
代码分析基于: go1.24
关键结构
Location
// location 结构代表着一个存储 Go 变量的抽象位置
type location struct {
n ir.Node // 关联变量或表达式的 AST 节点
curfn *ir.Func // 所属函数
edges []edge // 从该位置出发的所有数据流边
loopDepth int // 循环嵌套深度
// PPARAMOUT 变量:这些是函数的返回值参数。在 Go 的编译器中,函数的返回值被表示为特殊类型的参数(PPARAMOUT)。
// 索引从 1 开始:如果一个 location 代表一个返回值,其 resultIndex 就是该返回值在函数返回值列表中的位置(从1开始计数)。
// 非返回值为 0:对于不是返回值的变量,这个字段值为 0。
// 如果一个参数只泄漏到函数的返回值中(而不是泄漏到堆上或其他地方),那么这个参数可能不需要在堆上分配。
resultIndex int
// derefs and walkgen are used during walkOne to track the
// minimal dereferences from the walk root.
derefs int // 解引用次数,>= -1
walkgen uint32 // 遍历标记,避免循环
dst *location // 指向当前位置的下一个直接赋值目标位置
dstEdgeIdx int //存储指回当前位置的边在目标位置的边列表中的索引
// queued 用于给 walkAll 函数跟踪当前变量的 Location 是否处于待遍历的队列中
queued bool
// attrs 是一个用于存储 Location 各种属性的 Bitset
attrs locAttr
// paramEsc records the represented parameter's leak set.
paramEsc leaks
captured bool // 是否被闭包捕获?
reassigned bool // 是否被重新赋值?
addrtaken bool // 是否有取地址操作?
}
LocAttr
type locAttr uint8
const (
// 标志变量地址发生逃逸,必须进行堆分配。
attrEscapes locAttr = 1 << iota
// 表示表达式的地址是否在当前语句执行后仍然有效,即其存储空间是否不能立即被重用。
attrPersists
// 表示从该位置可达的指针所指向的内存是否可能被修改。这主要用于字符串到字节切片的转换优化。
attrMutates
// 表示从该位置可达的闭包是否可能在不跟踪其结果的情况下被调用。这用于优化间接闭包调用。
attrCalls
)
Edge
// edge 结构体表示数据流图中 location 之间的一条边
type edge struct {
src *location // 源变量位置
derefs int // 解引用次数 >= -1
notes *note // 用于生成诊断信息,帮助开发者理解为什么某些变量会逃逸到堆上
}
Hole
// hole 结构体保存着表达式逃逸分析的判定结果上下文
// 例如:得到 p 在表达式 "x = **p" 中的判定结果, 我们将创建一个 hole 结构
// 其中 dst==x, derefs==2
type hole struct {
dst *location
derefs int // >= -1
notes *note
// addrtaken indicates whether this context is taking the address of
// the expression, independent of whether the address will actually
// be stored into a variable.
addrtaken bool
}
edge 结构体也能携带类似的信息(src、derefs 和 notes),那为什么还需要 hole 作为中间层呢?
- 抽象层次不同:
hole代表一个"上下文"或"消费位置",它是对表达式求值的环境的抽象edge代表两个具体location之间的实际数据流关系
- 处理逻辑的分离:
hole允许在实际创建 edge 之前进行各种条件检查和转换- 通过
flow()方法,可以集中处理各种特殊情况(如自引用、空目标等)
- 复用和组合:
hole可以被创建一次然后多次使用- 可以通过
shift()、deref()、addr()等方法修改和组合hole - 支持像
teeHole()这样的高级操作,将一个值"分流"到多个目标
逃逸分析步骤
在Go编译过程中,逃逸分析发生在中间代码生成阶段。编译器会遍历抽象语法树(AST),构建数据流图,分析每个变量的作用域和引用关系。具体步骤如下:
- 变量引用追踪:编译器标记所有变量的声明位置,并跟踪其传递路径。例如,若变量
x被作为指针参数传递给另一个函数,或通过return语句返回,则可能触发逃逸。 - 逃逸条件判定:根据以下标准判断变量是否需要逃逸:
- 指针逃逸:函数返回局部变量的指针(如
return &x); - 动态类型逃逸:变量被赋值给
interface{}、any类型(如fmt.Println(x)); - 闭包引用逃逸:闭包函数捕获外部作用域的变量(如闭包内引用外层函数的局部变量);
- 栈空间不足:变量占用的内存超过栈的容量限制(如大尺寸的切片或结构体);
- 发送到 Channel 的变量;
- 指针逃逸:函数返回局部变量的指针(如
- 优化策略应用:对于未逃逸的变量,编译器优先分配在栈上;对于确定逃逸的变量,插入
runtime.newobject调用以在堆上分配内存。
逃逸分析源码
入口函数
// src/cmd/compile/internal/escape/escape.go
// 逃逸分析入口函数
// 从 ir 中获取所有函数表达式进行分析
func Funcs(all []*ir.Func) {
ir.VisitFuncsBottomUp(all, Batch)
}
批量分析
// Batch performs escape analysis on a minimal batch of
// functions.
func Batch(fns []*ir.Func, recursive bool) {
var b batch
// heapLoc 代表"堆内存"这一抽象概念。它不是程序中的实际变量,而是一个标记位置,表示堆内存的语义特性。
// 当分析中发现一个变量需要分配在堆上时,会建立从该变量到 heapLoc 的边。这表示该变量的生命周期延伸到了堆上,需要堆分配。
// 赋值标记表示被 heapLoc 关联的 location 对应的变量:逃逸到堆上、变量在语句执行后仍然存在、变量可能被修改、可能通过该变量调用函数。
b.heapLoc.attrs = attrEscapes | attrPersists | attrMutates | attrCalls
// mutatorLoc 代表"可能修改内存"这一抽象概念。它是一个标记位置,用于追踪内存修改操作。
// 这有助于追踪哪些变量可能被修改,特别是在优化字符串到字节切片转换时非常重要。
// 当分析中发现一个操作可能修改内存(如通过指针写入)时,会建立从该操作到 mutatorLoc 的边。
// 赋值标记表示被 mutatorLoc 关联的 location 对应的变量:变量可能被修改。
b.mutatorLoc.attrs = attrMutates
// calleeLoc 代表"可能被调用"这一抽象概念。它是一个标记位置,用于追踪函数调用,尤其是间接调用和闭包调用。
// 当分析中发现一个函数值可能被调用时,会建立从该函数值到 calleeLoc 的边。
// 这有助于追踪哪些闭包可能被调用,从而做出更准确的逃逸分析决策。
// 赋值标记表示被 calleeLoc 关联的 location 对应的变量:可能通过该变量调用函数。
b.calleeLoc.attrs = attrCalls
...
// 首先针对非闭包函数构建数据流图
for _, fn := range fns {
if !fn.IsClosure() {
// walkFunc 会遍历所有函数,针对内部的不同表达式都会有特定处理规则
// 根据表达式类型进行逃逸分析。
b.walkFunc(fn)
}
}
// 再针对闭包进行分析
for _, closure := range b.closures {
b.flowClosure(closure.k, closure.clo)
}
b.closures = nil
// 标记显式逃逸变量,包括:
// 使用类型参数的泛型类型;
// 某些特定的编译器指示;
// 有明确逃逸标记的变量;
// 语言规范要求必须在堆上分配的情况
for _, loc := range b.allLocs {
// 遍历所有 location, 检查堆分配原因
if why := HeapAllocReason(loc.n); why != "" {
// 通过 hole 这个辅助结构,构建逃逸变量 location 到 heapLoc 之间的关联边
b.flow(b.heapHole().addr(loc.n, why), loc)
}
}
// 传播和分析隐式逃逸,包括但不限于:
// 通过指针链接传递的逃逸;
// 由于生命周期关系导致的逃逸;
// 闭包捕获的变量逃逸;
// 接口和反射导致的逃逸;
b.walkAll()
b.finish(fns)
}
在 Go 编译器的逃逸分析过程中,代码会先处理非闭包函数,然后再处理闭包函数。由于闭包函数是在其他函数(称为"外层函数")的上下文中定义的匿名函数。闭包可以访问和修改其外层函数中定义的变量,这些变量称为"自由变量"。为了正确分析闭包函数,编译器需要先了解外层函数中变量的使用情况:
- 变量重分配情况:外层函数中的变量是否被重新赋值。
- 变量地址使用情况:外层函数中的变量是否有其地址被使用。
通过先分析非闭包函数,编译器已经收集了关于变量重分配和地址使用的信息。基于这些信息,编译器可以为每个闭包做出最优的捕获决策。闭包通常在以下情况下通过引用捕获变量:
- 变量在外层函数中被重新赋值:如果变量的值在外层函数中改变,闭包需要看到最新的值。
- 变量的地址被使用:如果变量的地址被传递给其他函数或存储在某处,变量需要有一个稳定的内存位置。
- 变量被多个闭包共享:如果多个闭包引用同一个变量,它们需要看到彼此的修改。
在不需要引用捕获的情况下,值捕获通常更高效:
- 变量不被重新赋值:如果变量在定义后不再改变,值捕获就足够了。
- 变量的地址不被使用:如果没有代码使用变量的地址,不需要为变量分配稳定的内存位置。
- 闭包只读取变量:如果闭包只读取变量而不修改它,值捕获通常更高效。
func (b *batch) flow(k hole, src *location) {
if k.addrtaken {
src.addrtaken = true
}
dst := k.dst
if dst == &b.blankLoc {
return // 特殊处理:忽略流向空白位置
}
if dst == src && k.derefs >= 0 { // dst = dst, dst = *dst, ...
return // 特殊处理:自引用
}
if dst.hasAttr(attrEscapes) && k.derefs < 0 { // dst = &src
// 特殊处理:逃逸
...
// 标记源位置为逃逸并记录原因
src.attrs |= attrEscapes | attrPersists | attrMutates | attrCalls
return
}
// 只有在通过了所有检查后,才创建实际的边
dst.edges = append(dst.edges, edge{src: src, derefs: k.derefs, notes: k.notes})
}
隐式逃逸传播和分析
walkAll 函数的主要目的是计算所有位置对(locations)之间的最小解引用次数。这个函数负责协调整个逃逸分析过程。walkOne 函数计算从根位置(root)到所有其他位置的最小解引用次数,同时传播逃逸属性。
walkAll 函数流程:
func (b *batch) walkAll() {
// We use a work queue to keep track of locations that we need
// to visit, and repeatedly walk until we reach a fixed point.
//
// We walk once from each location (including the heap), and
// then re-enqueue each location on its transition from
// !persists->persists and !escapes->escapes, which can each
// happen at most once. So we take Θ(len(e.allLocs)) walks.
// LIFO queue, has enough room for e.allLocs and e.heapLoc.
todo := make([]*location, 0, len(b.allLocs)+1)
enqueue := func(loc *location) {
if !loc.queued {
todo = append(todo, loc)
loc.queued = true
}
}
for _, loc := range b.allLocs {
enqueue(loc)
}
enqueue(&b.mutatorLoc)
enqueue(&b.calleeLoc)
enqueue(&b.heapLoc)
var walkgen uint32
for len(todo) > 0 {
root := todo[len(todo)-1]
todo = todo[:len(todo)-1]
root.queued = false
walkgen++
b.walkOne(root, walkgen, enqueue)
}
}
- 初始化工作队列:创建一个足够容纳所有 location 的 LIFO(后进先出)队列。
- 初始化分析起点:将所有已知位置(
b.allLocs)入队,将特殊位置入队:mutatorLoc(表示可能修改状态的操作)、calleeLoc(表示被调用函数)、heapLoc(表示堆内存)。通过enqueue函数确保每个位置只入队一次(使用queued标志)。 - 迭代分析过程:使用
walkgen计数器跟踪不同的分析轮次,对每个位置调用walkOne函数进行详细分析,持续处理队列中的位置,直到队列为空,表示达到稳定状态。 - 固定点迭代:迭代直到没有新的位置需要处理,即达到"固定点",当位置从非逃逸变为逃逸或从非持久变为持久时,会重新入队进行再次分析
walkOne 函数流程:
// walkOne 函数计算从根位置(root)到所有其他位置的最小解引用次数
func (b *batch) walkOne(root *location, walkgen uint32, enqueue func(*location)) {
// 使用类似 Bellman-Ford 的算法计算最短路径,
// 但考虑到地址操作产生负边(negative edges),限制解引用计数不小于 0
root.walkgen = walkgen
root.derefs = 0
root.dst = nil
if root.hasAttr(attrCalls) {
if clo, ok := root.n.(*ir.ClosureExpr); ok {
if fn := clo.Func; b.inMutualBatch(fn.Nname) && !fn.ClosureResultsLost() {
fn.SetClosureResultsLost(true)
// 重新分析闭包的返回值。
for _, result := range fn.Type().Results() {
enqueue(b.oldLoc(result.Nname.(*ir.Name)))
}
}
}
}
todo := []*location{root} // LIFO queue
for len(todo) > 0 {
l := todo[len(todo)-1]
todo = todo[:len(todo)-1]
derefs := l.derefs
var newAttrs locAttr
// 当 derefs < 0 时,表示位置 l 的地址流向根位置
addressOf := derefs < 0
if addressOf {
// 当代码执行 root = &l 然后 l = x 时,l 的地址流向了 root(即 root 指向 l),但 x 的地址并不会流向 root。
// 这里只是值复制,而非指针赋值。l 必须逃逸到堆上,因为它的地址被返回了。但 x 不需要逃逸,因为只有它的值复制给了 l,而它的地址没有"流出"函数作用域。
// 此时编译器通过设置解引用操作的下界为0来识别这种情况,防止在分析指针流时过度传递地址关系。
derefs = 0
// 如果根位置的生命周期超过位置 l,则 l 需要分配在堆上。
if b.outlives(root, l) {
...
newAttrs |= attrEscapes | attrPersists | attrMutates | attrCalls
} else
// 如果流向的位置带有标记 attrPersists,则 l 也需要标记 attrPersists。
if root.hasAttr(attrPersists) {
newAttrs |= attrPersists
}
}
if derefs == 0 {
newAttrs |= root.attrs & (attrMutates | attrCalls)
}
// 如果变量 l 的值流向了 root,l 是一个函数参数,且 root 是堆内存或对应的返回值参数。
// 那么编译器需要记录这个值流动关系,这个记录将用于后续对函数的标记(tagging)。
// 将影响函数签名中参数是否需要标记为逃逸,调用方如何处理传递给该函数的参数。
if l.isName(ir.PPARAM) {
if b.outlives(root, l) {
...
l.leakTo(root, derefs)
}
if root.hasAttr(attrMutates) {
l.paramEsc.AddMutator(derefs)
}
if root.hasAttr(attrCalls) {
l.paramEsc.AddCallee(derefs)
}
}
// 属性发生变化要重新入队检查
if newAttrs&^l.attrs != 0 {
l.attrs |= newAttrs
enqueue(l)
if l.attrs&attrEscapes != 0 {
continue
}
}
// 循环遍历所有边,更新引用计数
for i, edge := range l.edges {
if edge.src.hasAttr(attrEscapes) {
continue
}
d := derefs + edge.derefs
if edge.src.walkgen != walkgen || edge.src.derefs > d {
edge.src.walkgen = walkgen
edge.src.derefs = d
edge.src.dst = l
edge.src.dstEdgeIdx = i
todo = append(todo, edge.src)
}
}
}
}
- 初始化根位置:设置根位置的
walkgen(遍历生成标记)为当前迭代轮次,设置根位置的解引用计数derefs为 0,清除目标指针dst - 处理闭包特殊情况:检测根位置是否是闭包表达式,如果是闭包且在同一批处理中,标记闭包结果为"丢失"(lost),重新分析闭包的返回值.
- 从根节点开始开始层序遍历:
- 处理地址流动情况:当
derefs < 0时,表示位置l的地址流向根位置,如果根位置的生命周期超过位置l,则l需要分配在堆上(标记attrEscapes)。如果根位置带有标记attrPersists,则l也需要标记attrPersists。 - 处理值流动情况:当
derefs == 0时:根位置的变异(mutates)和调用(calls)属性传递给当前位置。 - 传播属性并递归:如果位置获得新属性,将其重新入队。递归处理位置的所有边,更新连接位置的解引用计数。
最小解引用次数
最小解引用次数表示从一个位置到另一个位置需要通过多少次间接引用操作才能访问到。
- 正值:表示需要多少次解引用才能从一个位置到达另一个位置
- 负值:表示取地址操作的次数(相当于"反向解引用")
- 零值:表示直接访问(无需解引用)
计算最小解引用次数的作用
- 确定逃逸性:如果变量 A 的地址被传递到变量 B(解引用次数为负),且 B 的生命周期比 A 长,则 A 需要逃逸到堆上。
- 确定变量间的引用关系:通过解引用次数跟踪变量之间的引用链。
- 优化内存分配:通过精确计算解引用次数,确定哪些变量可以安全地分配在栈上。避免不必要的堆分配,提高性能。
- 函数参数标记:记录函数参数的逃逸情况,特别是它们如何流向其他位置。为函数添加适当的逃逸标记,帮助内联和其他优化决策。
- 跟踪指针传递链:跟踪指针通过多少层间接引用后仍然可以访问到原始对象,方便确定复杂数据结构中哪些部分需要在堆上。
管理机制
每个goroutine的栈初始较小(通常为2KB),允许创建大量协程而不过度消耗内存。采用连续栈(contiguous stack),而非早期的分段栈(segmented stack)。当栈需要扩容时,分配更大的连续内存块,复制旧栈数据并释放旧内存,避免“热分裂”问题。当栈空间不足时(如深度递归或大量局部变量),Go运行时会动态扩容和缩容。扩容策略通常为双倍增长(如2KB → 4KB → 8KB),以减少频繁调整的开销。缩容策略是在栈空间利用率不足 25% 的情况下,进行折半缩容(如果折半后小于最小栈大小,则缩容到最小栈大小,最小栈大小根据操作系统变化)
栈操作
Go 语言中的执行栈由 stack 结构体表示,该结构体中只包含两个字段,分别表示栈的顶部和栈的底部,每个栈结构体都表示范围为 [lo, hi) 的内存空间:
// src/runtime/runtime2.go
// Stack describes a Go execution stack.
// The bounds of the stack are exactly [lo, hi),
// with no implicit data structures on either side.
type stack struct {
lo uintptr
hi uintptr
}
栈初始化
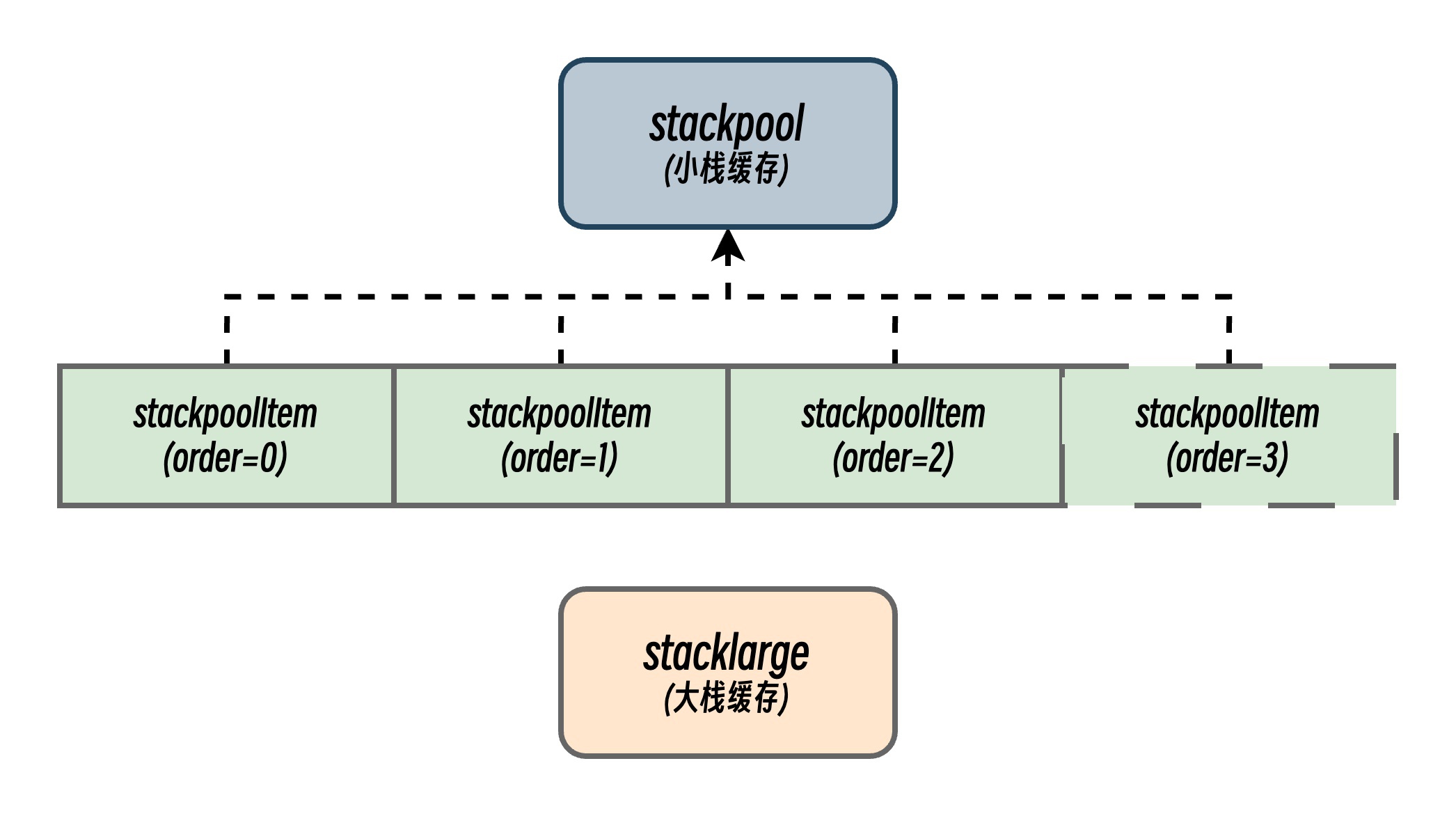
Golang 运行时的栈管理有两个重要的全局变量,stackpool 和 stacklarge。其中 stackpool 管理固定大小的小协程栈(默认 2KB~16KB)的全局内存池,按不同 order(尺寸级别)分桶(但是不同操作系统能缓存的栈大小可能不同)。
stackpool
// src/runtime/malloc.go
// Number of orders that get caching. Order 0 is FixedStack
// and each successive order is twice as large.
// We want to cache 2KB, 4KB, 8KB, and 16KB stacks. Larger stacks
// will be allocated directly.
// Since FixedStack is different on different systems, we
// must vary NumStackOrders to keep the same maximum cached size.
// OS | FixedStack | NumStackOrders
// -----------------+------------+---------------
// linux/darwin/bsd | 2KB | 4
// windows/32 | 4KB | 3
// windows/64 | 8KB | 2
// plan9 | 4KB | 3
_NumStackOrders = 4 - goarch.PtrSize/4*goos.IsWindows - 1*goos.IsPlan9
// Linux/Darwin/BSD/...:
// FixedStack = 2KB
// NumStackOrders = 4
// CacheSize: 2KB, 4KB, 8KB, 16KB
// Windows 32-bit:
// FixedStack = 4KB
// NumStackOrders = 3
// CacheSize: 4KB, 8KB, 16KB
// Windows 64-bit:
// FixedStack = 8KB
// NumStackOrders = 2
// CacheSize: 8KB, 16KB
// Plan9:
// FixedStack = 4KB
// NumStackOrders = 3
// CacheSize: 4KB, 8KB, 16KB
// src/runtime/stack.go
// Global pool of spans that have free stacks.
// Stacks are assigned an order according to size.
//
// order = log_2(size/FixedStack)
//
// There is a free list for each order.
var stackpool [_NumStackOrders]struct {
item stackpoolItem // 实际存储的栈内存段(mspan链表)
// 填充缓存行,避免伪共享
_ [(cpu.CacheLinePadSize - unsafe.Sizeof(stackpoolItem{})%cpu.CacheLinePadSize) % cpu.CacheLinePadSize]byte
}
type stackpoolItem struct {
_ sys.NotInHeap
mu mutex
span mSpanList
}
- 分桶策略:
order表示栈大小的对数级别(order=0对应 2KB,order=1对应 4KB,以此类推)。 - 缓存行填充:通过填充字节(
_字段)确保每个stackpoolItem独占缓存行,减少 CPU 缓存伪共享。 - 锁粒度:每个
order对应独立的锁(stackpool[i].item.mu),减少锁竞争。
stacklarge
// src/runtime/malloc.go
pageShift = _PageShift // src/runtime/sizeclasses.go 中定义值为 13
pageSize = _PageSize
_PageSize = 1 << _PageShift // 8192 Bytes(8KB)
...
// Per-P, per order stack segment cache size.
_StackCacheSize = 32 * 1024
// heapAddrBits 定义了 Go 运行时中堆地址位数(有效地址位的数量),用于确定内存寻址空间的大小、计算堆的内存布局和确定内存地址映射数据结构的大小和索引方式。
// 这种复杂计算的原因是不同硬件架构和操作系统对地址空间有不同的限制:
// 1. 大多数 64 位平台限制为 48 位地址(虽然地址是64位,但实际有效位只有 48 位);
// 2. iOS/ARM64特别限制为 40 位地址(历史原因和兼容性考虑,iOS14 放弃支持后提升到 48 位);
// 3. WebAssembly 有 4GB 内存限制,需要 32 位地址;
// 4. 32 位平台通常用 32 位地址;
// 5. MIPS32 只能访问低 2GB 虚拟内存,所以限制为 31 位;
// 6. Linux 虽然支持扩展到 57 位地址,但是大部分情况下都低于 48 位;
// 7. ppc64, mips64, and s390x 硬件上支持 64 位随机地址,但还是先遵循 Linux 系统的限制。
heapAddrBits = (_64bit*(1-goarch.IsWasm)*(1-goos.IsIos*goarch.IsArm64))*48 + (1-_64bit+goarch.IsWasm)*(32-(goarch.IsMips+goarch.IsMipsle)) + 40*goos.IsIos*goarch.IsArm64
...
// src/runtime/stack.go
// Global pool of large stack spans.
var stackLarge struct {
lock mutex
free [heapAddrBits - pageShift]mSpanList // free lists by log_2(s.npages)
}
- 分桶策略:按页数的对数分组(例如
log2(2 pages)对应 16KB 内存)。 - 全局锁:所有分桶共享一把锁(
stackLarge.lock),大栈分配频率较低,锁竞争影响较小。
stackinit
// src/runtime/stack.go
func stackinit() {
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
for i := range stackpool {
stackpool[i].item.span.init()
lockInit(&stackpool[i].item.mu, lockRankStackpool)
}
for i := range stackLarge.free {
stackLarge.free[i].init()
lockInit(&stackLarge.lock, lockRankStackLarge)
}
}
- 栈缓存对齐校验:确保
_StackCacheSize是页大小的倍数(如 8KB 页,_StackCacheSize默认 32KB)。 - stackpool 初始化:每个
order的mSpanList链表初始化为空。并为每个order初始化独立的互斥锁(lockRankStackpool定义锁的优先级)。 - stackLarge 初始化:所有分桶的
mSpanList初始化为空,初始化全局锁stackLarge.lock。
stackpoolalloc
这个函数负责为 goroutine 从栈池中分配指定大小阶(order)的栈。如果栈池中没有可用的栈,它会从堆内存中分配一个新的内存段(span)来创建新的栈。
// src/runtime/stack.go
// Allocates a stack from the free pool. Must be called with
// stackpool[order].item.mu held.
func stackpoolalloc(order uint8) gclinkptr {
list := &stackpool[order].item.span
s := list.first
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
if s == nil {
// no free stacks. Allocate another span worth.
s = mheap_.allocManual(_StackCacheSize>>_PageShift, spanAllocStack)
if s == nil {
throw("out of memory")
}
if s.allocCount != 0 {
throw("bad allocCount")
}
if s.manualFreeList.ptr() != nil {
throw("bad manualFreeList")
}
osStackAlloc(s)
s.elemsize = fixedStack << order
for i := uintptr(0); i < _StackCacheSize; i += s.elemsize {
x := gclinkptr(s.base() + i)
x.ptr().next = s.manualFreeList
s.manualFreeList = x
}
list.insert(s)
}
x := s.manualFreeList
if x.ptr() == nil {
throw("span has no free stacks")
}
s.manualFreeList = x.ptr().next
s.allocCount++
if s.manualFreeList.ptr() == nil {
// all stacks in s are allocated.
list.remove(s)
}
return x
}
- 尝试获取空闲 mspan:从目标
order分桶的mSpanList中获取第一个mspan。 - 分配新 mspan:若分桶为空,向堆管理器
mheap_申请一个新的mspan(大小为_StackCacheSize>>_PageShift个页,默认 4 页 32KB)。 - 切割 mspan:将新
mspan切割为多个等长栈块(大小为fixedStack << order),构建空闲链表。 - 分配栈块:从
mspan的空闲链表中取出第一个栈块返回。 - 更新链表:若当前
mspan无剩余栈块,将其从分桶链表中移除。
栈分配
编译器通过编译期链接阶段在函数调用前插入栈检查指令,在运行时即可触发栈的分配和扩容。以 amd64 架构为例,栈检查指令是借助以下函数插入的:
// src/cmd/internal/obj/{{arch}}/obj{{x}}.go
// e.g.
// x86 -> obj6.go
// arm64 -> obj7.go
// loong64 -> obj.go
// riscv -> obj.go
func preprocess(ctxt *obj.Link, cursym *obj.LSym, newprog obj.ProgAlloc) {
...
var regg int16
if !p.From.Sym.NoSplit() {
// Emit split check and load G register
p, regg = stacksplit(ctxt, cursym, p, newprog, autoffset, int32(textarg))
} else if p.From.Sym.Wrapper() {
// Load G register for the wrapper code
p, regg = loadG(ctxt, cursym, p, newprog)
}
...
}
...
var Linkamd64 = obj.LinkArch{
Arch: sys.ArchAMD64,
...
Preprocess: preprocess,
...
}
上面这段代码是 Go 编译器(cmd/compile)中用于插入栈扩容检查逻辑的关键部分,主要作用是调用 stacksplit 在函数入口处插入栈大小检查和对 runtime.morestack 的调用,确保协程栈空间足够执行当前函数。
// src/cmd/internal/obj/{{arch}}/obj{{x}}.go
// e.g.
// x86 -> obj6.go
// arm64 -> obj7.go
// loong64 -> obj.go
// riscv -> obj.go
// 插入栈检查和栈分裂代码到 Prologue 中
func stacksplit(ctxt *obj.Link, cursym *obj.LSym, p *obj.Prog, newprog obj.ProgAlloc, framesize int32, textarg int32) (*obj.Prog, int16) {
...
// runtime·morestack 调用结束后会跳回到这里
startPred := p
// 获取存储着 g 的寄存器
var rg int16
p, rg = loadG(ctxt, cursym, p, newprog)
if framesize <= abi.StackSmall {
// 处理小栈情况
...
} else if framesize <= abi.StackBig {
// 处理中等大小的栈
...
} else {
// 处理大栈的情况
...
}
// 插入跳转逻辑
jls := obj.Appendp(p, newprog)
jls.As = AJLS
jls.To.Type = obj.TYPE_BRANCH
...
// 根据情况选择合适的系统调用,构造 Call 指令
call := obj.Appendp(pcdata, newprog)
call.Pos = cursym.Func().Text.Pos
call.As = obj.ACALL
call.To.Type = obj.TYPE_BRANCH
call.To.Name = obj.NAME_EXTERN
morestack := "runtime.morestack"
switch {
case cursym.CFunc():
morestack = "runtime.morestackc"
case !cursym.Func().Text.From.Sym.NeedCtxt():
morestack = "runtime.morestack_noctxt"
}
call.To.Sym = ctxt.Lookup(morestack)
...
jmp := obj.Appendp(unspill, newprog)
jmp.As = obj.AJMP
jmp.To.Type = obj.TYPE_BRANCH
jmp.To.SetTarget(startPred.Link)
jmp.Spadj = +framesize
jls.To.SetTarget(spill)
if q1 != nil {
q1.To.SetTarget(spill)
}
...
}
本质上上述这段代码基本是基于不同的情况插入不同汇编指令,以实现检查和扩容,完成检查和扩容后,将继续执行本应执行的代码。以下是翻译的部分伪代码:
// 普通 Go 函数
// 小型栈: SP <= stackguard
CMPQ SP, 16(R14) // R14 保存 g 指针,比较 SP 与 g.stackguard0
JLS morestack // 如果 SP <= stackguard0,跳转到 morestack 调用
// C 函数调用
// 小型栈: SP <= stackguard
CMPQ SP, 24(R14) // R14 保存 g 指针,比较 SP 与 g.stackguard1
JLS morestack // 如果 SP <= stackguard1,跳转到 morestack 调用
// 普通 Go 函数
// 大型栈: SP-framesize <= stackguard-StackSmall
LEAQ -(framesize-StackSmall)(SP), R12 // R12 = SP-(framesize-StackSmall)
CMPQ R12, 16(R14) // 比较 R12 与 g.stackguard0
JLS morestack // 如果 R12 <= stackguard0,跳转到 morestack 调用
// C 函数调用
// 大型栈: SP-framesize <= stackguard-StackSmall
LEAQ -(framesize-StackSmall)(SP), R12 // R12 = SP-(framesize-StackSmall)
CMPQ R12, 24(R14) // 比较 R12 与 g.stackguard0
JLS morestack // 如果 R12 <= stackguard0,跳转到 morestack 调用
// 超大栈: 需要防止下溢
MOVQ SP, R12 // 保存 SP 到 R12
SUBQ -(framesize-StackSmall)(SP), R12 R12 = SP-(framesize-StackSmall)
JCS morestack // 如果减法产生溢出(进位标志位设置),直接跳转到 morestack
CMPQ R12, 16(R14) // 比较 R12 与 g.stackguard0
JLS morestack // 如果 R12 <= stackguard0,跳转到 morestack 调用
// C 函数调用
// 超大栈: 需要防止下溢
MOVQ SP, R12 // 保存 SP 到 R12
SUBQ -(framesize-StackSmall)(SP), R12 // R12 = SP-(framesize-StackSmall)
JCS morestack // 如果减法产生溢出(进位标志位设置),直接跳转到 morestack
CMPQ R12, 24(R14) // 比较 R12 与 g.stackguard0
JLS morestack // 如果 R12 <= stackguard0,跳转到 morestack 调用
morestack:
NOP SP
CALL runtime·morestack // 调用栈扩容代码
JMP start_of_splitstack // 跳转回 splitstack 重新检查
而在运行时创建新的 Goroutine 时,会在 runtime.malg 函数中调用 runtime.stackalloc 函数申请新的栈内存,进行函数调用时依赖编译器插入的 runtime.morestack 中检查栈空间是否充足;
func malg(stacksize int32) *g {
newg := new(g)
if stacksize >= 0 {
stacksize = round2(stackSystem + stacksize)
systemstack(func() {
// 初始化栈空间
newg.stack = stackalloc(uint32(stacksize))
})
newg.stackguard0 = newg.stack.lo + stackGuard
newg.stackguard1 = ^uintptr(0)
// Clear the bottom word of the stack. We record g
// there on gsignal stack during VDSO on ARM and ARM64.
*(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0
}
return newg
}
// src/runtime/stack.go
// stackalloc 分配 n 字节大小的栈
//
// stackalloc 必须运行在系统固定大小的栈上
// 因为使用了 Per-P 资源,不能进行栈分裂
// 栈分裂可能导致 P 被抢占和循环调用 stackalloc 导致死循环
//
//go:systemstack
func stackalloc(n uint32) stack {
// 必须运行在调度器栈(g0)上,避免栈扩容时的死锁
thisg := getg()
if thisg != thisg.m.g0 {
throw("stackalloc not on scheduler stack")
}
// 栈大小必须是 2 的幂次方(如 2KB、4KB、8KB...)
if n&(n-1) != 0 {
throw("stack size not a power of 2")
}
...
var v unsafe.Pointer
if n < fixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
var x gclinkptr
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
// 从全局池分配:
// 若禁用缓存(stackNoCache);
// 无 P(thisg.m.p==0);
// 处于禁止抢占状态(preemptoff!="",一般处于 GC 阶段)。
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
// 否则优先从当前 P 的本地缓存分配
c := thisg.m.p.ptr().mcache
x = c.stackcache[order].list // 从本地缓存获取
if x.ptr() == nil {
stackcacherefill(c, order) // 缓存为空则从全局池填充
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next // 移动缓存指针
c.stackcache[order].size -= uintptr(n) // 更新缓存链表
}
v = unsafe.Pointer(x)
} else { // 大栈分配(n 较大)
var s *mspan
// 计算需要的页数(npage)和对数(log2npage)
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// 尝试从大栈缓存(stackLarge)分配
// 大栈缓存(stackLarge):按对数分组管理空闲内存段(mspan),直接分配整块内存。
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
// 大栈缓存为空,尝试从堆空间申请内存分配大栈。
if s == nil {
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}
...
}
stackalloc 是 Go 运行时栈管理的核心函数,负责在协程栈扩容时,根据请求大小选择最优路径(本地缓存、全局池、大栈缓存或堆)分配内存。其通过精细化锁策略、内存复用和分级管理,实现了高并发场景下的高效安全栈分配,支撑 Go 轻量级协程模型的动态栈特性。
栈扩容
栈分配一节中提到过,编译器通过编译期在函数调用前插入栈检查指令,在运行时即可触发栈的分配和扩容。主要是在函数入口处根据情况插入对 runtime.morestack/runtime.morestackc/runtime.morestack_noctxt 函数的调用(不同的 CPU 架构在逻辑和指令上略有不同)。
// src/runtime/asm_amd64.s
// Called during function prolog when more stack is needed.
//
// The traceback routines see morestack on a g0 as being
// the top of a stack (for example, morestack calling newstack
// calling the scheduler calling newm calling gc), so we must
// record an argument size. For that purpose, it has no arguments.
TEXT runtime·morestack(SB),NOSPLIT|NOFRAME,$0-0
// Cannot grow scheduler stack (m->g0).
get_tls(CX)
MOVQ g(CX), DI // DI = g,获取当前 g
MOVQ g_m(DI), BX // BX = m,获取当前 m
// Set g->sched to context in f.
MOVQ 0(SP), AX // f's PC,获取调用 morestack 时的返回地址(PC)
MOVQ AX, (g_sched+gobuf_pc)(DI) // 保存到当前 g 的调度上下文(gobuf.pc)
LEAQ 8(SP), AX // f's SP,计算栈指针(SP)位置
MOVQ AX, (g_sched+gobuf_sp)(DI) // 保存到 gobuf.sp
MOVQ BP, (g_sched+gobuf_bp)(DI) // 保存基址寄存器(BP)
MOVQ DX, (g_sched+gobuf_ctxt)(DI) // 保存上下文(ctxt)
MOVQ m_g0(BX), SI // SI = m.g0,获取 m.g0
CMPQ DI, SI // 对比 curg 是否为 m.g0
JNE 3(PC) // 比对不是 g0, 跳转执行下一个检查
CALL runtime·badmorestackg0(SB) // 由于 g0 为系统栈,不应该执行 morestack 进行扩容
CALL runtime·abort(SB)
// Cannot grow signal stack (m->gsignal).
MOVQ m_gsignal(BX), SI // SI = m.gsignal,获取 m.gsignal
CMPQ DI, SI // 对比 curg 是否为 m.gsignal
JNE 3(PC) // 比对不是 m.gsignal, 跳转执行下一个检查
CALL runtime·badmorestackgsignal(SB)
CALL runtime·abort(SB)
NOP SP
// 从栈上偏移量为 8 的位置加载值到 AX 寄存器。这个值是函数 f 的调用者的程序计数器(返回地址)。
MOVQ 8(SP), AX
// 将 AX 中的调用者 PC 值保存到 BX 寄存器指向的 M 结构体的 morebuf.pc 字段。
// 此前已经将 g.m 保存到 BX 中
MOVQ AX, (m_morebuf+gobuf_pc)(BX)
// 计算 SP+16 的地址并加载到 AX 寄存器。
// 这是函数 f 的调用者的栈指针位置。
LEAQ 16(SP), AX
// 将计算出的调用者 SP 值保存到 M 的 morebuf.sp 字段。
MOVQ AX, (m_morebuf+gobuf_sp)(BX)
// 将 DI 寄存器中的值(当前 goroutine 的 g 指针)保存到 M 的 morebuf.g 字段。
// 这记录了正在执行栈扩容的 goroutine。
MOVQ DI, (m_morebuf+gobuf_g)(BX)
// Call newstack on m->g0's stack.
MOVQ m_g0(BX), BX // BX = m.g0,获取当前 m.g0
MOVQ BX, g(CX) // 将当前线程的 g 设为 g0
MOVQ (g_sched+gobuf_sp)(BX), SP // 切换到 g0 的栈
MOVQ (g_sched+gobuf_bp)(BX), BP // 恢复 g0 的 BP
CALL runtime·newstack(SB) // 执行栈扩容
CALL runtime·abort(SB) // crash if newstack returns
RET
// src/runtime/stack.go
//go:nowritebarrierrec
func newstack() {
thisg := getg()
// TODO: double check all gp. shouldn't be getg().
// 检查栈是否在设置 fork 状态后被扩容,避免破坏子进程状态。
if thisg.m.morebuf.g.ptr().stackguard0 == stackFork {
throw("stack growth after fork")
}
// 确保触发栈扩容的 Goroutine(m.morebuf.g)是当前运行的 Goroutine(m.curg),防止状态不一致。
if thisg.m.morebuf.g.ptr() != thisg.m.curg {
...
throw("runtime: wrong goroutine in newstack")
}
gp := thisg.m.curg
// 当 Goroutine 的 throwsplit 标志为 true 时,表示当前处于禁止栈分裂的场景(如执行原子操作或持有锁)。
// 不应该执行栈分裂,直接崩溃。
if thisg.m.curg.throwsplit {
...
throw("runtime: stack split at bad time")
}
...
// 检查栈底指针合法性
if gp.stack.lo == 0 {
throw("missing stack in newstack")
}
sp := gp.sched.sp
// 根据 CPU 架构修正栈指针指向
if goarch.ArchFamily == goarch.AMD64 || goarch.ArchFamily == goarch.I386 || goarch.ArchFamily == goarch.WASM {
// The call to morestack cost a word.
sp -= goarch.PtrSize
}
...
// 校验栈指针指向合法性,检查栈溢出
if sp < gp.stack.lo {
...
throw("runtime: split stack overflow")
}
...
// 计算新栈大小:新栈大小为旧栈的 2 倍,均摊多次扩容的成本。
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
// 根据函数最大栈帧需求(funcMaxSPDelta),调整 newsize 确保容纳新帧
if f := findfunc(gp.sched.pc); f.valid() {
max := uintptr(funcMaxSPDelta(f))
needed := max + stackGuard
used := gp.stack.hi - gp.sched.sp
for newsize-used < needed {
newsize *= 2
}
}
// 调试下才有的情况,不扩容强制迁移栈
if stackguard0 == stackForceMove {
newsize = oldsize
}
// 若新栈超过 maxstacksize(默认 1MB)或 maxstackceiling(环境变量设置),抛出栈溢出异常。
if newsize > maxstacksize || newsize > maxstackceiling {
...
throw("stack overflow")
}
// 切换为栈复制状态
casgstatus(gp, _Grunning, _Gcopystack)
// 栈复制
copystack(gp, newsize)
...
// 重新切换为执行状态
casgstatus(gp, _Gcopystack, _Grunning)
// 重新调度 goroutine
gogo(&gp.sched)
}
栈缩容
Golang 通过插入了检测和扩容代码保证了运行时占空间的动态分配,同时还会对栈进行缩容操作对内存占用的进行优化。
// src/runtime/mgcmark.go
func scanstack(gp *g, gcw *gcWork) int64 {
...
if gp == getg() {
throw("can't scan our own stack")
}
...
if isShrinkStackSafe(gp) {
// 如果可以安全进行栈缩容操作,则直接执行栈缩容
shrinkstack(gp)
} else {
// 否则,先进行标记,等待下次进入同步安全点时再执行栈缩容
gp.preemptShrink = true
}
...
}
从上述代码可以了解到,Go GC 在标记过程中会扫描 Goroutine 的执行栈做可达性分析,标灰可达的对象,在此过程中会一并对执行栈进行检查,确认是否可以进行缩容。如果符合条件可以安全缩容,则直接进行缩容。否则会先将 Goroutine 的 preemptShrink 变量标记为 true,等待其他位置触发缩容。
// src/runtime/stack.go
func newstack() {
...
gp := thisg.m.curg
...
if preempt {
...
if gp.preemptShrink {
// 当前为同步安全点,可以执行之前标记的栈缩容操作
gp.preemptShrink = false
shrinkstack(gp)
}
...
}
...
}
从上述代码可以得知,之前在 GC 阶段标记的 preemptShrink 会在 newstack 中直接触发缩容。
func shrinkstack(gp *g) {
// 确保栈有效
if gp.stack.lo == 0 {
throw("missing stack in shrinkstack")
}
// 确保当前执行 shrinkstack 的代码有权限修改目标 goroutine 的栈
// 不处于 _Gscan 状态
if s := readgstatus(gp); s&_Gscan == 0 {
// 当前代码在系统栈上运行,且目标是当前 M 的用户 G
if !(gp == getg().m.curg && getg() != getg().m.curg && s == _Grunning) {
throw("bad status in shrinkstack")
}
}
// 再次确认当前是安全的栈缩容时机
if !isShrinkStackSafe(gp) {
throw("shrinkstack at bad time")
}
// 防止在执行 C 库调用期间收缩栈,这可能导致难以追踪的指针问题。
if gp == getg().m.curg && gp.m.libcallsp != 0 {
throw("shrinking stack in libcall")
}
// 关闭栈缩容功能, 直接返回
if debug.gcshrinkstackoff > 0 {
return
}
// 不允许收缩 GC 后台标记工作器的栈,这是由于标记工作器有特殊的栈使用模式
f := findfunc(gp.startpc)
if f.valid() && f.funcID == abi.FuncID_gcBgMarkWorker {
return
}
// 计划将栈缩小到当前大小的一半
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2
// 如果缩小后会小于最小栈大小(fixedStack,通常是 2KB),则不进行缩容
if newsize < fixedStack {
return
}
// 计算当前栈使用量(从栈顶到SP,加上nosplit函数保留空间)
// 仅当使用量小于总栈空间的1/4(即使用率低于25%)时才进行缩容
avail := gp.stack.hi - gp.stack.lo
if used := gp.stack.hi - gp.sched.sp + stackNosplit; used >= avail/4 {
return
}
...
copystack(gp, newsize)
}
Golang 会在适当时机缩小栈,回收未使用的内存。其中包含多重检查,确保栈缩容操作的安全性。只有低于 1/4 使用率阈值,才会进行栈缩容,有效平衡内存效率和缩容频率。
func isShrinkStackSafe(gp *g) bool {
// 当 goroutine 正在执行系统调用时,syscallsp 不为 0。此时栈缩小是不安全的,原因有两点:
// 系统调用可能有指向 goroutine 栈的指针。
// 系统调用相关的栈帧通常缺乏精确的指针映射信息,这会导致在栈复制时无法正确追踪和更新指针。
if gp.syscallsp != 0 {
return false
}
// 当 goroutine 处于异步安全点时,同样缺乏所有栈帧的精确指针映射。
// 异步安全点是指在程序执行过程中可以安全暂停 goroutine 的位置,但这些位置可能没有完整的栈指针信息。
if gp.asyncSafePoint {
return false
}
// 当 goroutine 因为 channel 操作而被暂时挂起(parking)时,不能安全地缩小栈。
// 这是因为在 goroutine 调用 gopark 函数停泊在 channel 上,
// 到 gp.activeStackChans 被设置的这个时间窗口内,可能存在对栈的引用尚未被完全记录。
if gp.parkingOnChan.Load() {
return false
}
// 这是一种特殊情况,当满足以下三个条件时,不能缩小栈:
// 执行跟踪(execution tracing)功能已启用;
// goroutine 处于等待状态(_Gwaiting);
// goroutine 的等待原因是为了让自己可供垃圾收集器使用;
// 这种情况下,goroutine 实际上是在系统栈上执行的,执行跟踪器可能需要获取 goroutine 栈的跟踪信息。修改栈会干扰这个过程。
if traceEnabled() && readgstatus(gp)&^_Gscan == _Gwaiting && gp.waitreason.isWaitingForGC() {
return false
}
return true
}
isShrinkStackSafe 函数是 Go 栈管理系统中的关键安全检查机制,它通过检查多种可能导致不安全栈缩小的条件,确保栈调整操作只在完全安全的情况下进行。
栈复制
// 复制 g 的栈到新分配的栈空间
// 调用方需要先将 g 的状态切换为 Gcopystack
func copystack(gp *g, newsize uintptr) {
// 当 goroutine 正在执行系统调用时,syscallsp 不为 0。此时栈缩小是不安全的,原因有两点:
// 系统调用可能有指向 goroutine 栈的指针。
// 系统调用相关的栈帧通常缺乏精确的指针映射信息,这会导致在栈复制时无法正确追踪和更新指针。
if gp.syscallsp != 0 {
throw("stack growth not allowed in system call")
}
old := gp.stack
// 检查栈指针,空栈指针非法
if old.lo == 0 {
throw("nil stackbase")
}
// 通过栈顶指针 sched.sp 确定已使用的栈大小
used := old.hi - gp.sched.sp
// 通知 GC 控制器栈大小的变化,确保能正确扫描新栈。
gcController.addScannableStack(getg().m.p.ptr(), int64(newsize)-int64(old.hi-old.lo))
// 分配新栈
new := stackalloc(uint32(newsize))
if stackPoisonCopy != 0 {
fillstack(new, 0xfd)
}
...
// 计算新旧栈顶的地址差,用于后续指针调整
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi
// 若 Goroutine 未在通道操作中(!gp.activeStackChans),直接调整 Sudogs 指针。
// 否则,通过 syncadjustsudogs 同步并复制可能被其他 Goroutine 修改的栈部分,避免数据竞争。
ncopy := used
if !gp.activeStackChans {
if newsize < old.hi-old.lo && gp.parkingOnChan.Load() {
// 检查栈空间大小,因 channel 阻塞挂起时缩小栈可能导致其他
// Goroutine 通过 sudog.elem 访问已释放的旧栈内存,产生数据竞争(Data Race)。
throw("racy sudog adjustment due to parking on channel")
}
adjustsudogs(gp, &adjinfo)
} else {
// Goroutine 可能已释放 Channel 锁。
// 其他 Goroutine 正通过 sudog.elem 写入其栈内存(如发送数据到该 Goroutine 栈上的变量)。
// 直接复制栈可能导致写入冲突或数据丢失。
// 找到其他 Goroutine 可能写入的 栈内存最高地址(sghi)。
// 该地址以下的栈区域可能存在并发写入,需特殊处理。
adjinfo.sghi = findsghi(gp, old)
// 同步 Channel 操作,确保其他 Goroutine 完成对旧栈的写入。
// 复制从 sghi 到栈顶(old.hi)的栈数据(这部分可能被并发修改,需原子性复制)。
// 返回已复制的数据量,更新剩余需复制的数据量 ncopy。
ncopy -= syncadjustsudogs(gp, used, &adjinfo)
}
// memmove 将旧栈内容复制到新栈,保留已使用部分(ncopy 字节)。
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// 调整栈中包含指针的结构:
// 上下文(adjustctxt):调整 Goroutine 上下文中的栈指针(如函数调用链)。
// Defer 和 Panic(adjustdefers, adjustpanics):更新延迟调用和异常处理结构中的栈引用。
// 栈帧指针(adjustframe):遍历新栈帧,修正函数返回地址、局部变量等指针。
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
if adjinfo.sghi != 0 {
adjinfo.sghi += adjinfo.delta
}
// 切换至新栈:
// 更新 Goroutine 的栈引用
// 重置 gp.stackguard0
// 重置栈指针 gp.sched.sp
gp.stack = new
gp.stackguard0 = new.lo + stackGuard // NOTE: might clobber a preempt request
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// 调整新栈的栈帧信息
var u unwinder
for u.init(gp, 0); u.valid(); u.next() {
adjustframe(&u.frame, &adjinfo)
}
// 释放原有的栈空间
if stackPoisonCopy != 0 {
fillstack(old, 0xfc)
}
stackfree(old)
}
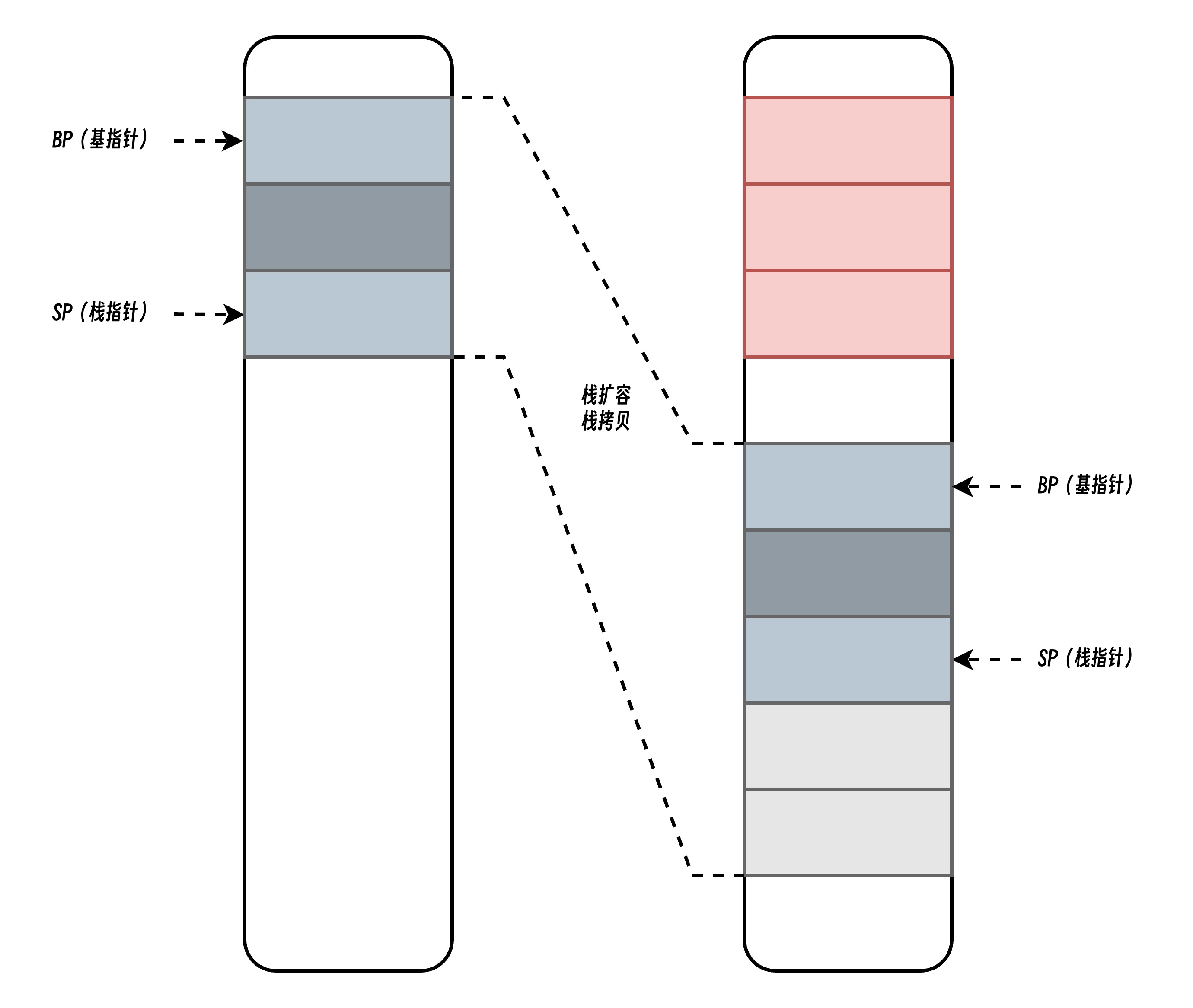
栈帧调整
栈复制后涉及到栈帧和栈帧内指针变量的调整,相关的调整是通过调用 adjustpointers 函数完成的。
位向量(bitvector)的作用
bitvector 结构体是编译器提供的关于栈帧内存布局的信息,它包含了一个位图,用于标记栈帧中哪些位置存储的是指针:
type bitvector struct {
n int32 // number of bits
bytedata *uint8
}
每个位对应栈上一个指针大小(通常是 8 字节)的内存位置:
- 位值为 1:表示该位置存储的是指针(需要调整)
- 位值为 0:表示该位置存储的是标量值(非指针,无需调整)
这些位向量信息是在编译时由 Go 编译器生成的:
- 编译器进行逃逸分析和类型分析,确定每个函数的栈帧中哪些变量是指针类型。
- 编译器为每个函数生成栈帧布局的元数据,包括位向量信息。
- 这些元数据被嵌入到可执行文件中,运行时可以访问。
func adjustpointers(scanp unsafe.Pointer, bv *bitvector, adjinfo *adjustinfo, f funcInfo) {
// scanp:要扫描的内存起始地址
// bv:描述该内存区域的位向量
// adjinfo:包含栈调整信息(旧栈范围、偏移量等)
minp := adjinfo.old.lo
maxp := adjinfo.old.hi
delta := adjinfo.delta
num := uintptr(bv.n)
useCAS := uintptr(scanp) < adjinfo.sghi
for i := uintptr(0); i < num; i += 8 {
...
b := *(addb(bv.bytedata, i/8)) // 获取一个字节(8位)的位向量数据
for b != 0 { // 只要还有位被设置,将持续遍历
j := uintptr(sys.TrailingZeros8(b)) // 找到最低的被设置为 1 的位
b &= b - 1 // 清除最低为 1 的位,准备处理下一个位
pp := (*uintptr)(add(scanp, (i+j)*goarch.PtrSize)) // 计算指针位置
retry:
// 调整指针指向
p := *pp
if f.valid() && 0 < p && p < minLegalPointer && debug.invalidptr != 0 {
// 发现非法指针,可能是存活分析出错
getg().m.traceback = 2
print("runtime: bad pointer in frame ", funcname(f), " at ", pp, ": ", hex(p), "\n")
throw("invalid pointer found on stack")
}
if minp <= p && p < maxp { // 如果指针指向旧栈
...
if useCAS {
// 对于可能受并发影响的内存(如 channel 接收槽),使用 CAS 原子操作调整指针
ppu := (*unsafe.Pointer)(unsafe.Pointer(pp))
if !atomic.Casp1(ppu, unsafe.Pointer(p), unsafe.Pointer(p+delta)) {
goto retry
}
} else {
// 调整指针值
*pp = p + delta
}
}
}
}
}
栈释放
//
// stackfree must run on the system stack because it uses per-P
// resources and must not split the stack.
//
//go:systemstack
func stackfree(stk stack) {
gp := getg()
v := unsafe.Pointer(stk.lo)
n := stk.hi - stk.lo
// 确保栈大小是 2 的幂
if n&(n-1) != 0 {
throw("stack not a power of 2")
}
// 确保栈的大小计算正确
if stk.lo+n < stk.hi {
throw("bad stack size")
}
...
// 如果启用了 efence(错误检测)或 stackFromSystem(从系统分配栈)
if debug.efence != 0 || stackFromSystem != 0 {
// 如果启用了错误检测或栈释放故障检测,则调用 sysFault 将内存标记为不可访问
if debug.efence != 0 || stackFaultOnFree != 0 {
sysFault(v, n)
} else {
// 否则直接调用 sysFree 释放系统内存并更新统计信息
sysFree(v, n, &memstats.stacks_sys)
}
return
}
...
// 只有符合大小的栈才进行缓存。
// 1. 小于当前操作系统环境下的 fixedStack(如 linux: 2K)<<_NumStackOrders(如 linux: 4) = 16K(Linux)
// 2. 小于最大栈缓存大小(32K)
if n < fixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
x := gclinkptr(v)
// 根据不同情况选择不同的回收操作
if stackNoCache != 0 || gp.m.p == 0 || gp.m.preemptoff != "" {
// 不启用 per-P 栈缓存,没有绑定 p,g.m 被抢占
// 放入全局 stackpool
lock(&stackpool[order].item.mu)
stackpoolfree(x, order)
unlock(&stackpool[order].item.mu)
} else {
// 放入 P 的本地栈缓存
c := gp.m.p.ptr().mcache
if c.stackcache[order].size >= _StackCacheSize {
stackcacherelease(c, order)
}
x.ptr().next = c.stackcache[order].list
c.stackcache[order].list = x
c.stackcache[order].size += n
}
} else {
// 大栈场景,作为 span 回收
s := spanOfUnchecked(uintptr(v))
if s.state.get() != mSpanManual {
println(hex(s.base()), v)
throw("bad span state")
}
if gcphase == _GCoff {
// GC 未运行时,直接释放
osStackFree(s)
mheap_.freeManual(s, spanAllocStack)
} else {
// GC 运行时,放入大栈缓存。
// 不允许直接将分配给栈的 span 返回到堆上,避免和 GC 发生竞争。
log2npage := stacklog2(s.npages)
lock(&stackLarge.lock)
stackLarge.free[log2npage].insert(s)
unlock(&stackLarge.lock)
}
}
}
stackfree 函数是 Go 运行时系统中负责释放协程栈内存的函数,它根据栈的大小采取不同的回收策略:
- 小栈放入栈缓存(本地或全局)以便重用
- 大栈直接释放或放入大栈缓存
- 支持各种调试、追踪和内存安全工具
- 考虑了 GC 运行时的并发安全
这种设计既高效(通过缓存重用栈内存)又安全(考虑了并发和内存安全),是 Go 运行时高效管理大量 goroutine 的关键部分
栈分布变化示例
代码分析基于: go1.24.2
下面通过一个简单的 Go 代码了解函数调用过程中栈空间的变化。
// test.go
package main
func main() {
a := 3
b := 2
returnTwo(a, b)
}
func returnTwo(a, b int) (c, d int) {
tmp := 1
c = a + b
d = b - tmp
return
}
通过编译器生成汇编代码,仅保留了重要部分,需要注意的是,不同版本可能因为优化策略变化、调用规约的迭代导致生成的汇编代码不一致。
go tool compile -S -N -l test.go
下列汇编代码省略了部分 PCDATA 和 FUNCDATA 指令以及部分元数据信息。
// main.main 函数,程序主函数入口,需要分配 40Bytes 的栈空间
main.main STEXT size=60 args=0x0 locals=0x28 funcid=0x0 align=0x0
0x0000 00000 (test.go:3) TEXT main.main(SB), ABIInternal, $40-0
0x0000 00000 (test.go:3) CMPQ SP, 16(R14) // 比较 **栈指针寄存器 SP** 和 **内存地址 **16(R14)** 处的值**。
0x0004 00004 (test.go:3) JLS 53 // 根据比对结果跳转检查栈空间,如需扩容则进行扩容
0x0006 00006 (test.go:3) PUSHQ BP // 基址寄存器压栈
0x0007 00007 (test.go:3) MOVQ SP, BP // 将 SP 的值赋予 BP
0x000a 00010 (test.go:3) SUBQ $32, SP // SP 向下移动 32 字节(栈增长)
0x000e 00014 (test.go:4) MOVQ $3, main.a+24(SP) // 保存临时变量 a = 3,24(SP) 为伪寄存器
0x0017 00023 (test.go:5) MOVQ $2, main.b+16(SP) // 保存临时变量 b = 2,16(SP) 为伪寄存器
0x0020 00032 (test.go:6) MOVL $3, AX // AX 寄存器赋值 3,用于传参
0x0025 00037 (test.go:6) MOVL $2, BX // BX 寄存器赋值 2,用于传参
0x002a 00042 (test.go:6) CALL main.returnTwo(SB) // 压入 returnTwo 返回地址,开始 returnTwo 函数调用
0x002f 00047 (test.go:7) ADDQ $32, SP // SP 向上移动 32 字节(栈缩小)
0x0033 00051 (test.go:7) POPQ BP // 弹出并回复先前压入的调用方基址到基址寄存器中
0x0034 00052 (test.go:7) RET // 函数返回
0x0035 00053 (test.go:7) NOP
0x0035 00053 (test.go:3) CALL runtime.morestack_noctxt(SB) // 编译器插入的栈扩容检查
0x003a 00058 (test.go:3) JMP 0
// main.returnTwo 函数,需要分配 32 Bytes 的栈空间。
// NOSPLIT 代表不需要进行栈分裂操作,属于编译器优化行为,
// 当前版本的 ABI 调用规约已经提前预留好用于存储临时变量的栈空间。
main.returnTwo STEXT nosplit size=77 args=0x10 locals=0x20 funcid=0x0 align=0x0
0x0000 00000 (test.go:9) TEXT main.returnTwo(SB), NOSPLIT|ABIInternal, $32-16
0x0000 00000 (test.go:9) PUSHQ BP // 基址寄存器压栈
0x0001 00001 (test.go:9) MOVQ SP, BP // 将 SP 的值赋予 BP
0x0004 00004 (test.go:9) SUBQ $24, SP // 栈空间向下增长 24 字节
0x0008 00008 (test.go:9) MOVQ AX, main.a+40(SP) // 将入参 a 写入 40(SP)
0x000d 00013 (test.go:9) MOVQ BX, main.b+48(SP) // 将入参 b 写入 48(SP)
0x0012 00018 (test.go:9) MOVQ $0, main.c+16(SP) // 将临时变量 c 写入 16(SP)
0x001b 00027 (test.go:9) MOVQ $0, main.d+8(SP) // 将临时变量 d 写入 8(SP)
0x0024 00036 (test.go:10) MOVQ $1, main.tmp(SP) // 将临时变量 tmp 写入 0(SP)
0x002c 00044 (test.go:11) MOVQ main.a+40(SP), CX // 将入参 a 的值写入 CX 寄存器
0x0031 00049 (test.go:11) LEAQ (CX)(BX*1), AX // CX(a) + BX(b) 写入 AX,即计算 c=a+b
0x0035 00053 (test.go:11) MOVQ AX, main.c+16(SP) // 将计算结果 c=5 写入 16(SP)
0x003a 00058 (test.go:12) MOVQ main.b+48(SP), BX // 将 b 的值写入 BX 寄存器
0x003f 00063 (test.go:12) DECQ BX // 由于 tmp=1,直接优化成 DECQ 指令,计算 d=b-tmp
0x0042 00066 (test.go:12) MOVQ BX, main.d+8(SP) // 将计算结果 d=1 写入 8(SP)
0x0047 00071 (test.go:13) ADDQ $24, SP // SP 向上移动 24 字节(栈缩小)
0x004b 00075 (test.go:13) POPQ BP // 弹出并回复先前压入的调用方基址到基址寄存器中
0x004c 00076 (test.go:13) RET // 函数返回

小结
传统编程语言(如 C/C++、Java)通常为每个线程分配一个固定大小的、较大的栈(例如 1MB-8MB)。这种设计的缺点是:
- 内存浪费:大多数线程/函数调用远用不了这么大的栈空间,导致大量虚拟内存被预留和浪费。
- 扩展性差:由于每个线程都占用大量内存,能够创建的线程数量受到严重限制。创建十万个线程几乎是不可能的。
Go 的设计哲学完全不同:为每个 Goroutine 分配一个小的、可按需动态增长的独立栈。
- 每个 Goroutine 一个独立栈
这是最基本的概念。在 Go 中,栈不是与系统线程(Thread)绑定的,而是与 Goroutine 绑定的。当你创建一个新的 Goroutine (go func(){...}), Go 运行时会为其创建一个全新的栈。
- 小初始栈空间
- 初始大小:在现代的 64 位系统上,每个 Goroutine 的栈在创建时,初始大小仅为 2KB。
- 目的:这个极小的初始值使得创建 Goroutine 的成本非常低。创建十万个 Goroutine 也只占用约 200MB 内存(
100,000 * 2KB),这使得大规模并发成为可能。
- 动态栈增长(Contiguous Stack Growth)
这是 Go 栈管理的核心技术。当一个 Goroutine 的栈空间不足以容纳一个新的函数调用时(例如,函数需要很大的局部变量,或者调用链非常深),Go 运行时会自动进行栈扩容。
当前(Go 1.4 及以后)的实现方式——连续栈(Contiguous Stacks):
- 触发时机:在每个函数调用的入口处,编译器会插入一小段代码(称为“栈增长检查”或“Preamble”)。这段代码会检查当前函数的栈帧是否会超出剩余的栈空间。
- 扩容流程 (
morestack):- 如果检查发现空间不足,会调用运行时的
runtime.morestack函数。 runtime.morestack会暂停当前 Goroutine 的执行。- 运行时会分配一个新的、更大的栈(通常是旧栈大小的 2 倍)。
- 然后,将旧栈中的所有内容(整个调用栈的数据)完整地拷贝到新栈的起始位置。
- 更新 Goroutine 的内部指针(在
g结构体中),使其指向这个新栈。 - 释放旧的栈内存。
- 恢复 Goroutine 的执行,此时它已经在新的、更大的栈上运行了,原来的函数调用可以顺利进行。
- 如果检查发现空间不足,会调用运行时的
- 优点:
- 简单高效:虽然拷贝有成本,但函数调用可以直接使用指针,无需间接寻址,访问速度快。
- 解决了“热分裂”问题:避免了在紧密循环中频繁跨栈段调用的性能问题(见下文历史部分)。
- 动态栈收缩
为了防止 Goroutine 在经历一次短暂的深度调用后,永久占用一个巨大的栈,Go 运行时也支持栈的收缩。
- 触发时机:在垃圾回收(GC)期间。
- 收缩流程:
- GC 会扫描所有 Goroutine 的栈。
- 如果发现某个 Goroutine 的栈使用率非常低(例如,当前栈使用量小于栈总大小的 1/4),运行时就会执行收缩操作。
- 收缩过程与扩容类似:分配一个更小的栈(通常是当前大小的 一半),将有效数据拷贝过去,释放旧的大栈。
- 栈分配的位置
Goroutine 的栈本身是在堆上分配的。这听起来有点奇怪,但逻辑上是清晰的:
- 栈内存 (Stack Memory):指的是 Goroutine 用于函数调用、局部变量的那块内存区域。
- 这块内存区域本身,作为一个内存块,是由 Go 的堆内存管理器(即前文提到的
mheap)来分配和管理的。
这样做的好处是,栈的管理可以完全由 Go 运行时掌控,而无需依赖操作系统的线程栈机制。

